Single-Agent vs. Multi-Agent AI Systems for Data Extraction: A Strategic Guide for Biomedical Research
This article provides a comprehensive comparison of single-agent and multi-agent AI systems for data extraction, specifically tailored for researchers, scientists, and professionals in drug development.
Single-Agent vs. Multi-Agent AI Systems for Data Extraction: A Strategic Guide for Biomedical Research
Abstract
This article provides a comprehensive comparison of single-agent and multi-agent AI systems for data extraction, specifically tailored for researchers, scientists, and professionals in drug development. It covers the foundational principles of both architectures, explores methodological approaches and real-world applications in biomedical contexts like clinical trial data processing, addresses key troubleshooting and optimization challenges, and presents a rigorous validation framework for comparing performance against traditional methods. The guide synthesizes current evidence to help research teams make informed, strategic decisions on implementing AI for enhancing the accuracy and efficiency of evidence synthesis and data extraction workflows.
Understanding AI Agent Architectures: From Single Actors to Collaborative Teams
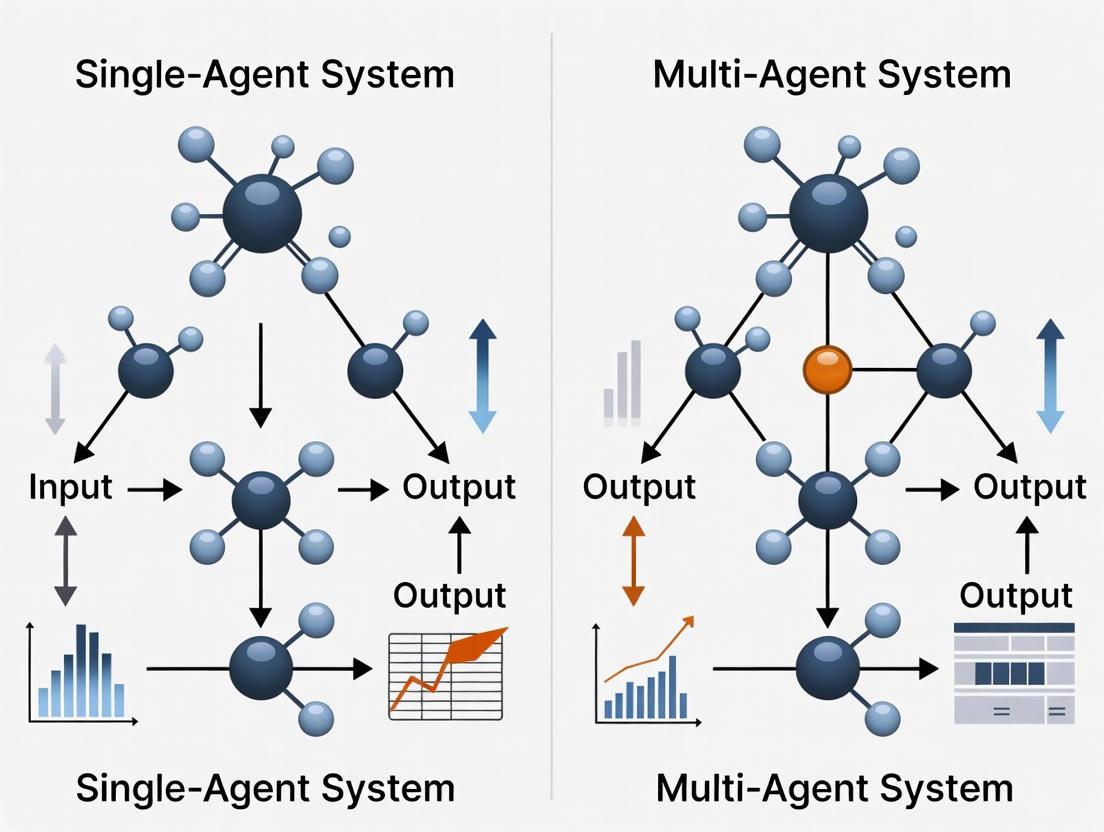
In the field of artificial intelligence, particularly for data-intensive research tasks, the choice between a Single-Agent System (SAS) and a Multi-Agent System (MAS) represents a fundamental architectural decision. A Single-Agent System operates as a unified entity, handling all aspects of a task from start to finish using a single reasoning engine, typically a Large Language Model (LLM) [1]. In contrast, a Multi-Agent System functions as a collaborative team, where multiple autonomous AI agents, each with potential specializations, work together by dividing a complex problem into manageable subtasks [2] [3].
For researchers in fields like drug development, understanding this distinction is critical. The core difference lies in the approach to problem-solving: a single agent maintains a continuous, sequential thread of thought, while multiple agents leverage parallel execution and specialized skills to tackle problems that are too complex for a single entity [4]. This guide provides an objective, data-driven comparison of these two paradigms to inform the design of AI systems for data extraction and scientific research.
Core Architectural Comparison
The architectural differences between single and multi-agent systems directly impact their capabilities, performance, and suitability for various research tasks. The table below summarizes their core characteristics.
Table 1: Fundamental Characteristics of Single-Agent vs. Multi-Agent Systems
| Aspect | Single-Agent System (SAS) | Multi-Agent System (MAS) |
|---|---|---|
| Core Architecture | A "single process" or unified entity [1]. | A team of collaborating autonomous agents [3]. |
| Execution Model | Sequential; completes step A before moving to step B [1]. | Parallel; multiple subtasks can be handled simultaneously [1] [2]. |
| Context Management | Unified, continuous context with no loss between steps [1]. | Distributed; complex sharing required, with each agent often having a context subset [1]. |
| Coordination Needs | None needed internally [1]. | Critical; requires protocols for communication and collaboration to avoid conflict [1] [5]. |
| Inherent Strength | Context continuity and high reliability [1]. | Parallel processing, scalability, and the ability to specialize [1] [3]. |
| Primary Challenge | Context window limits and sequential bottlenecks [1]. | Context fragmentation, coordination complexity, and potential for unpredictable behavior [1] [5]. |
Operational Workflows
The logical flow of each system type dictates its operational strengths and weaknesses. The following diagrams illustrate the fundamental workflows for each architecture.
Diagram 1: Single-Agent System Sequential Workflow
Diagram 2: Multi-Agent System Collaborative Workflow
Quantitative Performance Analysis
Empirical studies and industry benchmarks provide critical insights into the practical performance of each system architecture. Key quantitative differences are summarized below.
Table 2: Empirical Performance and Cost Comparison
| Performance Metric | Single-Agent System (SAS) | Multi-Agent System (MAS) | Data Source & Context |
|---|---|---|---|
| Token Usage | ~4x a standard chat interaction [1]. | ~15x a standard chat interaction [1]. | Measured by Anthropic, highlighting higher computational cost for MAS. |
| Relative Accuracy | Superior for tasks within advanced LLM capabilities [6]. | 1.1% - 12% higher accuracy for certain complex applications [6]. | An extensive empirical study found MAS advantages are task-dependent and diminishing with newer LLMs. |
| Deployment Cost | Lower inference cost [4]. | Potentially higher due to multiple LLM calls [4]. | Industry observation; cost scales with agent count and interaction complexity. |
| Response Latency | Lower response time [4]. | Potentially higher due to sequential agent hand-offs [4]. | Industry observation; parallel execution can mitigate this in some workflows. |
| Reliability & Debugging | High predictability; straightforward debugging [1]. | Lower predictability; complex debugging due to emergent behaviors [1]. | Inherent characteristic related to system architecture. |
Key Experimental Findings and Protocols
Recent research underscores that the performance gap between SAS and MAS is dynamic and highly dependent on the underlying LLM capabilities and task structure.
- Diminishing MAS Advantage with Advanced LLMs: A 2025 empirical study comparing SAS and MAS across various applications found that the performance benefits of multi-agent systems diminish as the capabilities of the core LLMs improve [6]. Frontier models like OpenAI-o3 and Gemini-2.5-Pro, with their advanced long-context reasoning and memory retention, can mitigate many limitations that originally motivated complex MAS designs [6].
- The "More Agents" Scaling Law: Contrary to the above, research from Tencent (2024) demonstrated that for certain problem types, simply scaling the number of agents in an ensemble leads to consistently better performance. This "Agent Forest" method uses a sampling phase (generating multiple responses from different agent instances) followed by a voting phase (selecting the best response via majority vote or similarity scoring). The study found that performance scales with agent count, and smaller models with more agents can sometimes outperform larger models with fewer agents [7].
- Hybrid Architectures for Optimal Performance: The same 2025 study proposed and validated a hybrid agentic paradigm, "request cascading," which dynamically routes tasks between SAS and MAS based on complexity [6]. This design was shown to improve accuracy by 1.1-12% while reducing deployment costs by up to 20% across various applications, suggesting that a flexible, non-dogmatic approach is often most effective [6].
The Researcher's Toolkit: System Implementation
Building and testing either type of agentic system requires a robust set of tools and methodologies, especially for high-stakes research applications.
Research Reagent Solutions
Table 3: Essential Components for Building and Evaluating AI Agents
| Component / Tool | Category | Function in Research & Development |
|---|---|---|
| LLMs (GPT-4, Claude, PaLM, LLaMA) [5] | Core Reasoning Engine | Provides the fundamental reasoning, planning, and natural language understanding capabilities for each agent. Model choice balances cost, performance, and safety. |
| Simulation Test Environment [8] | Validation Framework | Provides a controlled, reproducible, and adjustable environment to test agent behaviors and interactions safely before real-world deployment. |
| Orchestrator Frameworks [7] | Coordination Software | Manages overall workflow, routes tasks between specialized agents, and synthesizes final outputs (e.g., Microsoft's Magentic-One). |
| Quantitative Metrics [8] | Performance Measure | Tracks key performance indicators (KPIs) like response time, throughput, task success rate, and communication overhead. |
| Docker & Virtual Envs [7] | Deployment Infrastructure | Provides containerized and secure environments for executing agents, especially when tools or code execution are required. |
| Structured Communication [3] | Agent Interaction Protocol | Enables reliable data exchange between agents using standardized formats like JSON over HTTP or gRPC. |
| Ethyl 6-nitropicolinate | Ethyl 6-nitropicolinate, MF:C8H8N2O4, MW:196.16 g/mol | Chemical Reagent |
| 7-Fluoro-4-methoxyquinoline | 7-Fluoro-4-methoxyquinoline, MF:C10H8FNO, MW:177.17 g/mol | Chemical Reagent |
Protocol for System Testing and Validation
Rigorous testing is paramount for deploying reliable agentic systems in research. A structured, three-level methodology is recommended [8]:
- Unit Testing: Validate each agent's decision-making and behavior in isolation. Checks include correct rule-following and handling of unexpected inputs [8].
- Integration Testing: Run small groups of agents together to verify effective communication, deadlock avoidance, and correct shared outcomes [8].
- System Testing: Evaluate the full system under realistic conditions. Measure performance metrics and observe for coordination breakdowns. This stage should include stress tests, such as introducing communication failures or erroneous agent information, to validate system resilience and graceful recovery [8].
The choice between single and multi-agent systems is not a matter of one being universally superior. Instead, it is a strategic decision based on the nature of the research task, available resources, and required reliability [1] [4].
- Use a Single-Agent System when tasks are primarily sequential, state-dependent, and well-defined. Examples include refactoring a codebase, writing a detailed document, or performing a straightforward data extraction task where context continuity is paramount [1]. This architecture offers simplicity, reliability, and lower cost.
- Use a Multi-Agent System when faced with highly complex, multi-faceted problems that benefit from parallel execution and role specialization. Examples include broad market research, analyzing a complex scientific problem requiring multiple areas of expertise, or building a system that requires internal validation loops [1] [4]. This architecture provides scalability and the potential for higher accuracy on suitably complex tasks but at the cost of greater complexity and resource consumption.
The future of agentic systems in research appears to be moving toward flexible, hybrid models [6]. As a foundational 2025 study concluded, the question is not "SAS or MAS?" but rather a pragmatic "How can we best combine these paradigms?" [6]. The emerging hybrid paradigm, which dynamically selects the most efficient architecture per task, has already demonstrated significant improvements in both accuracy and cost-effectiveness, offering a promising path forward for data extraction and scientific research applications [6].
For researchers in drug development and data extraction, the choice between a single-agent and a multi-agent AI system is architectural. The performance, scalability, and reliability of research automation hinge on how effectively the core components of an AI agent—Planning, Memory, Tools, and Action—are implemented and orchestrated [9] [10]. This guide provides an objective, data-driven comparison of these two paradigms, focusing on their application in complex data extraction and research tasks. We break down the architectural components, present quantitative performance data, and detail experimental protocols to inform your research and development decisions.
Architectural Blueprint: Core Components of an AI Agent
Every AI agent, whether operating alone or in a team, is built upon a foundational architecture. Understanding these core components is essential for diagnosing performance and making informed design choices.
The Five-Layer Architecture
A typical AI agent architecture consists of five integrated layers that enable it to operate autonomously [9]:
- Perception: This is the agent's interface to the external world. It gathers and interprets raw data from its environment, which for a digital agent could be a user query, data from an API, or a document stream. The module processes this data into a standardized, usable format for subsequent layers [9] [10].
- Memory: This layer enables the agent to retain information across interactions. Short-term memory maintains the immediate context of an ongoing task or conversation, while long-term memory acts as a knowledge base, storing historical data, user preferences, and past experiences for recall in future sessions [9] [10]. Modern agents often use vector databases (e.g., Pinecone, FAISS) to store and semantically search embeddings of multimodal data [9].
- Reasoning & Decision-Making (Planning): This is the cognitive engine of the agent. Here, the Large Language Model (LLM) interprets the processed input from the Perception layer, consults Memory, and engages in Planning. It breaks down high-level goals into a sequence of actionable steps, makes strategic decisions, and determines the optimal path to achieve its objective [9] [10].
- Action & Execution: This layer translates decisions into outcomes. The agent executes its plan by interacting with external systems. This can involve calling APIs, running scripts, generating text, controlling software, or, in the case of physical agents, operating actuators [9] [10].
- Feedback Loop (Learning): This final layer enables the agent to learn and improve over time. It evaluates the outcomes of its actions through methods like reinforcement learning (rewarding success), human-in-the-loop feedback, or self-critique. The insights gained are used to update the agent's models and strategies for future tasks [9] [10].
Visualizing the Agent Architecture
The following diagram illustrates the continuous loop of information and decision-making through these five core layers.
Single-Agent vs. Multi-Agent Systems: A Comparative Analysis
The core architectural components manifest differently in single-agent and multi-agent systems, leading to distinct performance and capability profiles.
Defining the Paradigms
- Single-Agent System: A monolithic architecture where one intelligent agent handles the entire task lifecycle—from ingesting inputs and reasoning to using tools and generating outputs [11]. It manages its own memory, state, and connections to external tools or APIs.
- Multi-Agent System (MAS): A coordinated ecosystem of multiple specialized AI agents working together to achieve a shared goal [12]. A key feature is an orchestrator (or supervisor) that breaks down complex problems, delegates subtasks to specialized agents, and synthesizes their results, creating a form of "collective intelligence" [13] [11].
Performance and Characteristic Comparison
The table below summarizes the objective differences between the two paradigms, based on documented use cases and industry reports.
Table 1: Objective Comparison of Single-Agent vs. Multi-Agent Systems
| Criteria | Single-Agent System | Multi-Agent System |
|---|---|---|
| Architectural Core | Monolithic agent managing all components [11]. | Specialized agents for sub-tasks, coordinated by an orchestrator [13] [12]. |
| Task Complexity | Best for well-defined, linear tasks (e.g., simple Q&A, email summarization) [11]. | Excels at multidimensional problems (e.g., financial analysis, predictive maintenance) [12]. |
| Development & Cost | Faster to implement, lower initial cost, simpler debugging [12] [11]. | Complex to orchestrate, requires more technical expertise and computational resources [12] [11]. |
| Fault Tolerance | Single point of failure; agent failure halts the entire system [11]. | Inherent resilience; failure of one agent can be mitigated by others [13] [11]. |
| Scalability | Struggles with complex, scalable tasks; adding capabilities increases agent complexity exponentially [11] [14]. | Highly scalable and modular; agents can be optimized and added independently [13] [12]. |
| Typical Use Cases | Personal assistant, specialized chatbot, simple task automation [12] [11]. | Supply chain optimization, multi-criteria financial analysis, automated research [12] [15]. |
Quantitative Performance Data
Controlled experiments and internal industry evaluations provide measurable evidence of the performance differences. The following table compiles key quantitative findings.
Table 2: Experimental Performance Data
| Metric | Single-Agent Performance | Multi-Agent Performance | Experimental Context |
|---|---|---|---|
| Research Task Accuracy | Baseline | 90.2% improvement over single-agent baseline [15]. | Anthropic's internal eval: Multi-agent (Claude Opus + Sonnet) vs. single-agent (Claude Opus) on a research task [15]. |
| Contract Review Efficiency | Baseline | 60% reduction in review time [13]. | Law firms automating contract review with multi-agent systems [13]. |
| Operational Efficiency | Baseline | 35% reduction in unplanned downtime; 28% optimization in maintenance costs [12]. | Industrial predictive maintenance using multi-agent systems [12]. |
| Resource Consumption (Tokens) | Baseline (Chat) | ~15x more tokens than chat interactions [15]. | Anthropic's measurement of token usage in multi-agent research systems [15]. |
Experimental Protocols for Architectural Comparison
To validate the claims in Table 2 and objectively compare architectures, researchers can adopt the following experimental protocols.
Protocol 1: Multi-Agent Research Eval (Based on Anthropic)
This protocol tests the system's ability to handle complex, breadth-first research queries [15].
- Objective: To compare the accuracy and completeness of information retrieved by single-agent and multi-agent systems for a query requiring parallel information gathering.
- Task: "Identify all the board members of the companies in the Information Technology S&P 500."
- Experimental Groups:
- Group A (Single-Agent): A single, powerful LLM (e.g., Claude Opus) operates in a loop, using search tools sequentially.
- Group B (Multi-Agent): An orchestrator (Claude Opus) analyzes the query, spawns multiple sub-agents (Claude Sonnet) to research different companies in parallel, and synthesizes the findings.
- Metrics:
- Accuracy: Percentage of correctly identified board members.
- Completeness: Percentage of S&P 500 IT companies for which at least one board member was found.
- Token Usage: Total tokens consumed to complete the task.
- Methodology:
- A ground truth dataset of board members is established.
- Each system executes the task in a controlled environment with access to the same search tools.
- The final output is compared against the ground truth for accuracy and completeness.
- Token usage is logged for cost-efficiency analysis.
Protocol 2: Document Processing and Data Extraction Eval
This protocol measures efficiency in a key data extraction research scenario.
- Objective: To compare the time and accuracy of single-agent and multi-agent systems in processing complex documents and extracting specific data points.
- Task: Analyze a 100-page pharmaceutical research report to extract all drug compound names, associated trial phases, and primary efficacy endpoints.
- Experimental Groups:
- Group A (Single-Agent): A single agent processes the entire document sequentially.
- Group B (Multi-Agent): A system with specialized agents: a
document_parser, adata_extraction_agent(for compound names and endpoints), avalidation_agent(to check for consistency), and asummary_agent[13].
- Metrics:
- Time-to-Completion: Total time from task start to final output.
- F1 Score: Harmonic mean of precision and recall for extracted data points.
- Error Rate: Percentage of incorrectly extracted or hallucinated data points.
- Methodology:
- A set of annotated documents serves as the benchmark.
- Systems process the documents, and their outputs are captured.
- Extracted data is automatically and manually compared to the benchmark to calculate F1 score and error rate.
- Execution time is measured from the first agent call to the final output.
The Researcher's Toolkit: Essential Components for Replication
Table 3: Research Reagent Solutions for AI Agent Experimentation
| Item | Function in Experiment | Example Tools / Frameworks |
|---|---|---|
| Orchestration Framework | Manages workflow logic, agent communication, and task delegation in multi-agent systems. | LangGraph, CrewAI, AutoGen [13] [11] |
| Core LLM(s) | Serves as the reasoning engine for agents. Different models can be used for orchestrators and specialized workers. | GPT-4, Claude Opus/Sonnet, Llama [15] |
| Memory Layer | Provides short-term and long-term memory for agents to retain context and knowledge. | Redis (short-term), Vector Databases (Pinecone, Weaviate) [9] [11] |
| Tool & API Protocol | Standardizes and secures agent access to external tools, databases, and APIs. | Model Context Protocol (MCP) [16] |
| Evaluation Framework | Provides metrics and tools to quantitatively assess agent performance, accuracy, and cost. | Custom eval scripts, TruLens, LangSmith |
| 1-Octadecenylsuccinic Acid | 1-Octadecenylsuccinic Acid, MF:C22H40O4, MW:368.5 g/mol | Chemical Reagent |
| 4-Glycylphenyl benzoate hcl | 4-Glycylphenyl benzoate hcl, MF:C15H14ClNO3, MW:291.73 g/mol | Chemical Reagent |
Visualizing Multi-Agent System Workflows
The performance advantages of multi-agent systems stem from their orchestrated workflows. The following diagram illustrates the orchestrator-worker pattern used in advanced research systems.
The architectural breakdown confirms that the choice between single and multi-agent systems is not a matter of superiority, but of strategic fit. For researchers and drug development professionals, the decision matrix is clear:
- Choose a single-agent architecture for prototyping, simple data lookup tasks, or linear workflows where development speed and cost are primary constraints [11] [16].
- Choose a multi-agent architecture for complex data extraction research, analyzing multi-source documents, or any problem that requires parallel processing, domain specialization, and high reliability [13] [12] [15]. The quantitative data shows a significant performance uplift, albeit at a higher computational cost.
The future of automated research in scientific fields lies in leveraging the collective intelligence of multi-agent systems. As frameworks and models evolve, the cost of these systems is expected to decrease, making them an indispensable tool for accelerating discovery and innovation.
In the architectural landscape of artificial intelligence, the choice between single-agent and multi-agent systems represents a fundamental trade-off between simplicity and specialization. For researchers, scientists, and drug development professionals considering AI systems for data extraction research, single-agent systems offer a compelling proposition for well-defined, focused tasks. These systems employ one intelligent agent that handles the entire task lifecycle—from ingesting inputs and reasoning to tool use and output generation [11]. Unlike multi-agent approaches that distribute functionality across specialized subsystems, single-agent architectures maintain all context in one place, making them exceptionally suited for targeted applications where coordination overhead would otherwise diminish returns [17]. This guide objectively examines the performance characteristics of single-agent systems through experimental data and methodological analysis, providing a foundation for architectural decisions in research environments.
Performance Analysis: Quantitative Comparisons
Rigorous evaluation reveals distinct performance characteristics where single-agent systems demonstrate clear advantages in specific operational contexts. The following data synthesizes findings from controlled experiments and real-world implementations.
Table 1: System Performance Comparison in Specialized Tasks
| Performance Metric | Single-Agent System | Multi-Agent System | Experimental Context |
|---|---|---|---|
| Development Speed | Rapid implementation (hours to days) [11] | Extended development cycles | Prototyping workflows [17] [11] |
| Decision-making Latency | Faster direct decision-making [11] | Higher latency from inter-agent communication [17] | Time-sensitive research queries [11] |
| Implementation Time | 19% faster completion [18] | 19% slower completion [18] | Complex software development tasks [18] |
| System Reliability | Single point of failure [11] | Fault tolerance through agent redundancy [11] | High-availability research environments [11] |
| Debugging Complexity | Straightforward; single system to monitor [17] | Complex; requires tracing across multiple agents [17] | Error resolution in experimental workflows [17] |
Table 2: Architecture Suitability Analysis for Research Applications
| Research Task Profile | Single-Agent Recommendation | Performance Rationale |
|---|---|---|
| Focused Data Extraction | Strong recommendation | Lower latency, maintained context [17] [11] |
| Multi-Domain Research Questions | Not recommended | Limited domain expertise [17] [19] |
| Rapid Prototyping | Strong recommendation | Faster development cycles [17] [11] |
| Complex Workflow Orchestration | Not recommended | Limited coordination capabilities [19] [11] |
| Targeted Literature Review | Strong recommendation | Unified context management [17] |
Controlled experimentation demonstrates that for experienced developers working on well-defined tasks, single-agent systems can provide significant efficiency advantages. A randomized controlled trial (RCT) with experienced open-source developers revealed that AI-assisted work using primarily single-agent approaches took 19% longer than unaided work, contradicting developer expectations of 24% speedup [18]. This surprising result highlights that single-agent performance advantages are context-dependent and do not automatically translate to all scenarios, particularly those requiring deep specialization [18].
Experimental Protocols and Methodologies
Software Development Productivity RCT
Objective: Quantify the impact of single-agent AI assistance on implementation time for experienced developers working on familiar codebases [18].
Methodology:
- Participant Selection: 16 experienced developers from large open-source repositories (averaging 22k+ stars, 1M+ lines of code) with multi-year contribution histories [18]
- Task Selection: 246 real issues (bug fixes, features, refactors) valuable to the repository provided by developers [18]
- Randomization: Issues randomly assigned to AI-allowed or AI-disallowed conditions [18]
- AI Intervention: Developers used Cursor Pro with Claude 3.5/3.7 Sonnet (frontier models at study time) when allowed [18]
- Control: No generative AI assistance in disallowed condition [18]
- Measurement: Self-reported implementation time with screen recording verification [18]
- Compensation: $150/hour to ensure professional motivation [18]
Key Findings: Despite developer expectations of 24% speedup, single-agent AI assistance resulted in 19% longer implementation times across tasks averaging two hours each [18]. This performance pattern persisted across different outcome measures and estimator methodologies [18].
Legal Domain Task Specialization Study
Objective: Evaluate single-agent system performance on specialized legal tasks including legal information retrieval, question answering, and judgment prediction [19].
Methodology:
- Task Allocation: Single-agent systems assigned to focused legal tasks including legal information retrieval [20], legal question answering [19] [21] [11], and legal judgment prediction [21] [22]
- Performance Benchmarking: Comparison against multi-agent systems on complex, multi-faceted legal tasks [19]
- Analysis Metrics: Success rates, error types, context maintenance capabilities [19]
Key Findings: Single-agent systems demonstrated strong performance on focused legal tasks but showed limitations when faced with problems requiring diverse expertise or integrated reasoning [19]. Research literature significantly favors single-agent approaches in current implementations, reflecting their maturity for well-scoped applications [19].
Architectural Framework and Workflow
Single-agent systems employ streamlined architectures that consolidate functionality within a unified reasoning entity. The following diagram illustrates the core components and their interactions within a typical single-agent system for research applications:
Figure 1: Single-Agent Architecture for Research Tasks
The architectural workflow demonstrates how single-agent systems maintain unified context throughout task execution. The planning module serves as the central reasoning component that coordinates with memory, tools, and action modules without requiring inter-agent communication [19]. This integrated approach eliminates coordination overhead and maintains full context awareness throughout the task lifecycle [17].
The Researcher's Toolkit: Essential Components
Successful implementation of single-agent systems for research tasks requires specific components optimized for focused performance. The following table details these essential elements and their functions in research environments.
Table 3: Research Reagent Solutions for Single-Agent Systems
| Component | Function | Research Application Examples |
|---|---|---|
| Planning Module | High-level reasoning and task decomposition [19] | Breaking down research questions into executable steps [19] |
| Memory Component | Maintains context and state across interactions [19] | Preserving research context throughout data extraction [17] [19] |
| Tool Integration | Provides access to external APIs and databases [11] | Connecting to research databases, scientific APIs [11] |
| Action Module | Executes tasks and generates outputs [19] | Delivering extracted data, summaries, or analyses [19] |
| Model Context Protocol | Standardized connection to data sources [11] | Unified access to research data repositories [11] |
| Thrombin Receptor Agonist | Thrombin Receptor Agonist, MF:C81H118N20O23, MW:1739.9 g/mol | Chemical Reagent |
| Magl-IN-8 | MAGL Inhibitor Magl-IN-8 | Magl-IN-8 is a potent MAGL inhibitor for neurological disease, pain, and cancer research. For Research Use Only. Not for human or veterinary diagnostic or therapeutic use. |
Decision Framework for Research Applications
The following decision pathway provides a structured approach for researchers to evaluate when single-agent systems represent the optimal architectural choice:
Figure 2: Research Task Decision Pathway
This decision framework emphasizes that single-agent systems excel when tasks have narrow, well-defined scope and benefit from maintained contextual continuity [17]. For drug development professionals, this might include targeted literature extraction, focused data analysis from standardized experiments, or automated reporting on specific research metrics [17] [11].
Single-agent systems demonstrate unequivocal strengths for research tasks characterized by focused scope and requirements for contextual consistency. The experimental evidence indicates that these systems provide optimal performance when applied to problems matching their architectural strengths: lower latency, simplified debugging, reduced infrastructure overhead, and more straightforward maintenance [17]. For research organizations building AI capabilities for data extraction, single-agent systems represent the optimal starting point for most focused applications, with the potential to evolve toward multi-agent architectures only when tasks genuinely require diverse specialization [17] [11]. The experimental data reveals that performance advantages are context-dependent, requiring careful task analysis before architectural commitment [18]. For the research community, this evidence-based approach to system selection ensures that architectural complexity is introduced only when justified by clear functional requirements.
The automation of data extraction from complex scientific literature represents a critical challenge in accelerating research, particularly in fields like drug development and materials science. The central thesis of this guide is that for complex, multimodal data extraction tasks, multi-agent systems demonstrate marked advantages in precision, recall, and handling of complex contexts compared to single-agent systems, albeit with increased architectural complexity. The evolution of Large Language Models (LLMs) has powered both paradigms; single-agent systems utilize one powerful model to handle an entire task, while multi-agent systems decompose problems, delegating subtasks to specialized, coordinated agents [23] [24]. Recent empirical studies, including those in high-stakes domains like nanomaterials research, show that a multi-agent approach can significantly outperform even the most advanced single-model baselines by leveraging specialization, verification, and distributed problem-solving [6] [25]. This guide provides an objective comparison of these architectures, focusing on their performance in data extraction for research.
Quantitative Performance Comparison
The following tables summarize key performance indicators and characteristics from experimental studies and real-world implementations, highlighting the comparative effectiveness of single-agent versus multi-agent systems.
Table 1: Experimental Performance in Scientific Data Extraction
| Metric | Single-Agent System (GPT-4.1) | Multi-Agent System (nanoMINER) | Context / Dataset |
|---|---|---|---|
| Average Precision | Lower than MAS [25] | Consistently Higher [25] | Extraction from nanomaterials literature [25] |
| Average Recall | Lower than MAS [25] | Consistently Higher [25] | Extraction from nanomaterials literature [25] |
| F1 Score | 35.6% (Previous SOTA model) [26] | 80.8% [26] | Benchmark dataset of multimodal chemical reaction graphics [26] |
| Data Similarity to Manual Curation | 65.11% [25] | Precision ≥ 0.96 for kinetic parameters [25] | Nanozyme data extraction [25] |
| Parameter Extraction Precision | Varies, struggles with implicit data [25] | Up to 0.98 for parameters like Km, Vmax [25] | Nanozyme characteristics [25] |
| Crystal System Inference | Limited capability shown [25] | High capability from chemical formulas alone [25] | Nanomaterial characteristics [25] |
Table 2: Architectural and Operational Characteristics
| Characteristic | Single-Agent Systems | Multi-Agent Systems |
|---|---|---|
| Core Architecture | One intelligent entity handles the entire task [23] [27] | Multiple specialized agents collaborate [23] [3] |
| Scalability | Limited; struggles with growing complexity [23] [27] | Highly scalable; agents can be added/removed [23] [3] |
| Fault Tolerance | Single point of failure [23] | Robust; failure of one agent doesn't collapse system [23] [28] |
| Decision-Making | Fast, centralized, but narrow perspective [23] [27] | Collective, slower, but broader perspective [23] [27] |
| Communication Overhead | None or low [23] | High; requires coordination protocols [23] [27] |
| Problem-Solving Capability | Restricted to one perspective/strategy [23] | Distributed, collaborative, multiple perspectives [23] [29] |
| Best Suited For | Simple, well-defined tasks in controlled environments [23] [27] | Complex, dynamic tasks requiring collaboration [23] [28] |
Experimental Protocols and Methodologies
The nanoMINER Multi-Agent Protocol for Nanomaterial Data Extraction
A landmark 2025 study published in npj Computational Materials detailed the nanoMINER system, providing a rigorous protocol for comparing multi-agent and single-agent performance in extracting structured data from scientific literature on nanomaterials [25].
1. Objective: To automatically assemble datasets of nanomaterial and nanozyme properties from unstructured research articles and supplementary materials with precision rivaling manual curation by domain experts [25].
2. Agent Architecture and Workflow:
- Main (ReAct) Agent: Orchestrates the workflow, initialized with tools for text, image, and data extraction. It processes the full article text and coordinates with specialized agents [25].
- NER Agent: Based on a fine-tuned Mistral-7B or Llama-3-8B model, this agent extracts specific named entities (e.g., chemical formulas, properties) from the segmented text [25].
- Vision Agent: Leverages GPT-4o and a YOLO model to detect and interpret figures, tables, and schemes within the PDF, converting visual information into structured data [25].
3. Experimental Procedure:
- PDF Processing: Input documents are processed to extract raw text, images, and plots [25].
- Text Segmentation: The article text is split into chunks of 2048 tokens for efficient processing [25].
- Agent Coordination: The Main agent delegates tasks. The NER agent scans text segments, while the Vision agent analyzes visual data [25].
- Information Aggregation: The Main agent aggregates outputs from all agents, reconciles information from different modalities, and generates the final structured output [25].
- Benchmarking: The system's performance was benchmarked against strong baselines, including the multimodal GPT-4.1 and reasoning models (o3-mini, o4-mini), using standard precision, recall, and F1 scores on a manually curated gold-standard dataset [25].
Protocol for Comparative Performance Analysis
A separate extensive empirical study directly compared MAS and SAS across various agentic applications [6].
- Objective: To evaluate if the benefits of MAS over SAS diminish as the capabilities of frontier LLMs improve [6].
- Methodology: The study conducted head-to-head comparisons of MAS and SAS implementations on popular agentic tasks, measuring accuracy and deployment costs [6].
- Key Finding: The study confirmed the superior accuracy of MAS but also found that the performance gap narrows with more advanced base LLMs. This insight motivated the design of a hybrid "request cascading" paradigm, which dynamically chooses between SAS and MAS to optimize both efficiency and capability [6].
System Workflow Visualization
The fundamental difference between single-agent and multi-agent architectures lies in their workflow and coordination. The following diagram illustrates the comparative workflows of both systems in a data extraction pipeline.
Figure 1. Data Extraction Workflow: Single-Agent vs. Multi-Agent Systems. The Single-Agent System (top) uses one model for the entire task. The Multi-Agent System (bottom) uses an orchestrator to delegate subtasks to specialized agents (e.g., for text and vision), followed by aggregation and validation [23] [25].
The Scientist's Toolkit: Essential Frameworks and Models
Implementing these systems requires a selection of software frameworks and models. The table below details key "research reagent solutions" for building single or multi-agent data extraction systems.
Table 3: Key Tools and Frameworks for Building AI Agent Systems
| Tool Name | Type | Primary Function | Relevance to Data Extraction Research |
|---|---|---|---|
| AutoGen [29] | Multi-Agent Framework | Creates conversable AI agents that can work together and use tools. | Enables building collaborative agent teams for complex, multi-step extraction tasks. |
| CrewAI [28] [29] | Multi-Agent Framework | Orchestrates role-playing AI agents in a structured team. | Ideal for defining clear agent roles (e.g., "NER Specialist," "Data Validator"). |
| LangGraph [28] [29] | Multi-Agent Framework | Models agent interactions as stateful, cyclic workflows. | Manages complex, non-linear extraction pipelines where agent steps may loop. |
| GPT-4o / GPT-4.1 [25] | Multimodal LLM | Powers agents with strong reasoning and multimodal understanding. | Serves as a powerful base LLM for single agents or multiple agents in a MAS. |
| Llama-3-8B / Mistral-7B [25] | Foundational LLM | Provides capable, smaller-scale language understanding. | Can be fine-tuned for specific, cost-effective NER agent tasks within a MAS. |
| YOLO Model [25] | Computer Vision Tool | Detects and classifies objects within images and figures. | Used by a dedicated Vision Agent to extract data from charts and diagrams in papers. |
| Azure AI Foundry [3] | Production Platform | Builds and orchestrates specialized AI agents in long-running workflows. | Provides an enterprise-grade platform for deploying research extraction agents. |
| Jervinone | Jervinone, CAS:469-60-3, MF:C27H37NO3, MW:423.6 g/mol | Chemical Reagent | Bench Chemicals |
| Egfr/aurkb-IN-1 | EGFR/AURKB-IN-1|Dual Kinase Inhibitor|For Research | Bench Chemicals |
The empirical data and experimental protocols presented confirm the core thesis: multi-agent systems offer a powerful paradigm for complex data extraction in research. Their strength lies in specialization, validation through multi-step reasoning, and robustness derived from distributed problem-solving [28] [25]. While single-agent systems remain a valid choice for simpler, well-defined tasks due to their simplicity and lower computational overhead [23] [6], the comparative evidence shows that multi-agent systems consistently achieve higher precision and recall on complex, multimodal scientific extraction tasks [26] [25]. For researchers and drug development professionals aiming to automate the curation of high-quality datasets from the vast scientific literature, the multi-agent approach, implemented with the modern toolkit described, represents the current state-of-the-art. The emerging trend of hybrid systems that dynamically leverage both architectures promises to further enhance efficiency and capability in the future [6].
In the field of AI-driven data extraction, the choice between centralized (single-agent) and distributed (multi-agent) decision-making architectures represents a critical strategic decision for research and drug development professionals. These competing paradigms offer distinct trade-offs in control, efficiency, and adaptability that directly impact research outcomes and operational scalability. Centralized systems feature a single point of control where all decisions are processed through one authoritative agent, ensuring consistency but potentially creating bottlenecks [30] [31]. Conversely, distributed systems decentralize authority across multiple specialized agents, enabling parallel processing and localized decision-making while introducing coordination complexity [1] [32].
The relevance of these architectural patterns extends directly to scientific domains such as drug discovery, where automated research systems must process vast biomedical literature databases, experimental data, and clinical trial results. Understanding the fundamental characteristics, performance metrics, and implementation requirements of each approach allows research teams to align their AI infrastructure with specific project goals, whether prioritizing rigorous protocol adherence or exploratory data analysis.
Defining the Architectural Paradigms
Centralized (Single-Agent) Systems
Centralized decision-making architectures operate through a unified control point where a single agent maintains authority over all processing decisions and actions. This model functions as an integrated specialist that handles complex, state-dependent tasks through sequential execution, maintaining a continuous context throughout operations [1]. In practice, this might manifest as a singular AI agent responsible for end-to-end data extraction from scientific literature, maintaining consistent interpretation standards across all processed documents.
The defining characteristic of centralized systems is their stateful architecture, where early decisions directly inform subsequent actions without requiring inter-process communication [1]. This continuity proves particularly valuable for "write" tasks such as generating consolidated research reports or maintaining standardized data formats across multiple extractions. The unified context management ensures that information remains consistent without fragmentation across specialized subsystems, though this benefit becomes constrained as tasks approach the limits of the system's context window [1].
Distributed (Multi-Agent) Systems
Distributed decision-making architectures deploy multiple specialized agents that operate both independently and collaboratively, typically coordinated through a lead agent that decomposes objectives and synthesizes outputs [1]. This structure mirrors a research team with domain specialists, where different agents might separately handle literature retrieval, data normalization, evidence grading, and synthesis before integrating their findings.
This paradigm excels at "read" tasks that benefit from parallel execution, such as simultaneously analyzing multiple research databases or processing disparate data sources [1] [33]. The distributed context model allows each agent to operate with specialized instructions and tools, though this requires deliberate engineering to ensure proper information sharing between components [1]. The architectural flexibility supports both hierarchical coordination with a lead agent and swarm intelligence approaches with more peer-to-peer collaboration, each presenting distinct management challenges and opportunities for emergent problem-solving behaviors [1].
Comparative Analysis: Performance Trade-offs
The choice between centralized and distributed architectures involves measurable trade-offs across multiple performance dimensions. The following table synthesizes key comparative metrics based on documented implementations and experimental observations:
Table 1: Architectural Performance Comparison for Data Extraction Tasks
| Performance Dimension | Centralized (Single-Agent) Systems | Distributed (Multi-Agent) Systems |
|---|---|---|
| Context Management | Continuous, unified context with no information loss between steps [1] | Complex sharing required, risk of context fragmentation across agents [1] |
| Execution Speed | Sequential processing creates bottlenecks for parallelizable tasks [1] | Parallel execution significantly reduces latency for multi-faceted problems [1] |
| Computational Resources | ~4x chat tokens (baseline) [1] | ~15x chat tokens due to inter-agent communication [1] |
| Reliability & Predictability | High, with straightforward execution paths and deterministic behaviors [1] | Lower, with emergent behaviors and non-deterministic interactions [1] |
| Debugging & Maintenance | Transparent decision trails and simpler testing procedures [1] | Complex, non-deterministic patterns requiring advanced observability tools [1] |
| Scalability | Limited by central processing capacity and context window size [31] [1] | Highly scalable through addition of specialized agents [31] [1] |
| Fault Tolerance | Single point of failure - central agent failure disrupts entire system [31] [32] | Resilient - failure of individual agents doesn't necessarily collapse system [31] [32] |
| Best Suited Tasks | Sequential, state-dependent "write" tasks (code generation, report writing) [1] | Parallelizable, exploratory "read" tasks (research, multi-source analysis) [1] |
These quantitative differences manifest distinctly in research environments. Centralized architectures provide superior performance for generating standardized extraction reports or maintaining consistent data formatting across documents, while distributed systems excel at comprehensive literature reviews that require simultaneous database queries and comparative analysis [1]. The significant difference in computational resource requirements (token usage) represents a direct cost-benefit consideration, with distributed systems offering accelerated processing at substantially higher computational expense [1].
Decision Framework: Selecting the Appropriate Architecture
Task Characteristics Analysis
Research initiatives should evaluate their primary workload characteristics against architectural strengths. The "read" versus "write" distinction provides a foundational framework: tasks primarily involving information gathering, analysis, and comparison (read-intensive) naturally align with distributed architectures, while tasks centered on generating coherent outputs, synthesizing unified perspectives, or creating structured documents (write-intensive) benefit from centralized approaches [1].
Project complexity further refines this assessment. Straightforward extraction tasks with well-defined targets and consistent source materials may achieve optimal efficiency through centralized processing, while complex, multi-disciplinary research questions requiring diverse expertise and source integration typically benefit from distributed specialization [33]. Teams should also consider data dependency patterns - tightly coupled processes with significant state dependencies favor centralized control, while loosely coupled, modular operations can leverage distributed parallelism.
Organizational and Environmental Factors
Implementation context significantly influences architectural success. Organizational culture represents a particularly influential factor, with control-oriented environments often adapting more successfully to centralized models, while innovation-focused cultures may better leverage distributed approaches [34]. The BUILD framework (Be Open, Understand, Investigate, Leverage Opportunities, Drive Forward) provides a structured methodology for navigating these organizational dynamics when establishing decision-making structures [30].
Scalability requirements and resource constraints present additional considerations. Growing research operations with expanding data volumes and diversity typically benefit from distributed architectures' horizontal scaling capabilities [32]. Conversely, resource-constrained environments may prioritize the computational efficiency of centralized systems, particularly when handling sensitive data where consolidated governance simplifies compliance [32] [35]. Teams should honestly assess their technical infrastructure and expertise, as distributed systems demand robust coordination mechanisms and observability tooling to manage inherent complexity [1] [33].
Experimental Protocols and Validation Methodologies
Performance Benchmarking Framework
Rigorous architectural evaluation requires controlled measurement across defined experimental conditions. The following protocol establishes a standardized benchmarking approach:
Table 2: Experimental Reagents for Architecture Validation
| Research Component | Function in Experimental Protocol | Implementation Examples |
|---|---|---|
| Task Repository | Provides standardized tasks for consistent performance measurement across architectures | Curated set of data extraction challenges from scientific literature with validated response benchmarks |
| Evaluation Metrics Suite | Quantifies performance across multiple dimensions for comparative analysis | Precision/recall for data extraction, latency measurements, token consumption tracking, consistency scoring |
| Observability Infrastructure | Captures system behaviors and internal states for debugging and analysis | LangSmith Studio for agent tracing, custom logging for inter-agent communication, context window monitoring |
| Coordination Mechanisms | Enables communication and task management in distributed architectures | Research pads for shared memory, hierarchical delegation protocols, swarm collaboration patterns |
Experimental implementation should commence with baseline establishment using controlled tasks representing common research operations: targeted data extraction from known sources, multi-document synthesis, and complex query resolution across disparate databases. Each architecture processes identical task sets under standardized resource constraints, with performance measured across the metrics outlined in Table 2 [1] [33].
For distributed systems, specific coordination patterns should be explicitly defined and maintained throughout testing - whether hierarchical (lead agent with specialized workers) or swarm (peer-to-peer collaboration). Centralized systems should implement optimized context management strategies to maximize their unified information advantage. Result validation must include both quantitative metric collection and qualitative assessment by domain experts to evaluate practical utility beyond numerical scores [33].
Hybrid Architecture Experimental Design
Many research environments benefit from hybrid approaches that combine architectural elements. Experimental protocols should specifically test integration patterns that leverage centralized consistency for critical functions while distributing parallelizable components. One validated methodology implements a distributed research team (multiple specialized agents) with a centralized synthesis agent that consolidates findings into coherent outputs [33].
Another hybrid model maintains centralized governance and quality control while distributing execution across specialized components. This approach particularly suits regulated research environments where audit trails and protocol adherence remain mandatory. Experiments should measure hybrid performance against pure architectures using the same benchmarking framework, with particular attention to integration overhead and overall system coherence [32] [35].
Implementation Pathways and Operationalization
Technical Implementation Considerations
Successful operationalization requires matching architectural choices to technical capabilities. Centralized implementations benefit from frameworks that support extensive tool integration and state management within a unified context, such as LangGraph for complex workflows [33]. The critical technical consideration involves context window management and optimization strategies to maximize the single-agent's effectiveness without exceeding processing limits [1].
Distributed implementations demand robust inter-agent communication frameworks and specialized tooling for durable execution, observability, and coordination management [1]. Architectures must explicitly address context sharing mechanisms, whether through research pads, shared memory spaces, or structured message passing [33]. Production deployments require sophisticated monitoring to track inter-agent dependencies and identify emergent bottlenecks or conflicting behaviors.
Organizational Implementation Strategy
Architectural transitions should follow incremental pathways, beginning with pilot projects that match each approach's strengths to specific research initiatives. The BUILD framework provides a structured methodology for organizational alignment: cultivating openness to different architectural paradigms, developing deep understanding of each approach's motivations, investigating context-specific solutions, leveraging hybrid opportunities, and driving implementation through concrete action plans [30].
Successful implementation further requires establishing appropriate success metrics aligned with architectural goals - centralized systems measured by consistency and efficiency, distributed systems by scalability and comprehensive coverage [36]. Organizations should anticipate evolving needs by designing flexible infrastructures that can incorporate additional specialized agents or transition certain functions to centralized control as processes mature and standardize.
The centralized versus distributed decision-making dichotomy presents research organizations with fundamentally different approaches to AI-driven data extraction, each with demonstrated strengths across specific task profiles and operational environments. Centralized architectures deliver reliability, consistency, and efficiency for state-dependent "write" tasks, while distributed systems provide scalability, specialization, and parallel processing capabilities for exploratory "read" tasks.
Informed architectural selection requires honest assessment of research priorities, technical capabilities, and organizational context rather than ideological preference. The most sophisticated implementations increasingly adopt hybrid models that strategically combine centralized coordination with distributed execution, applying each paradigm to its most suitable functions. As AI capabilities advance, the fundamental trade-offs documented here will continue to inform strategic infrastructure decisions for research organizations pursuing automated data extraction and scientific discovery.
Implementing AI Agents for Data Extraction: Methodologies and Biomedical Use Cases
In data extraction research, the transition from single-agent to multi-agent systems represents a fundamental architectural shift to overcome inherent limitations in handling complex, multi-faceted tasks. Single-agent systems often struggle with cognitive load, error propagation, and scalability constraints when faced with sophisticated data extraction pipelines that require multiple specialized capabilities [14]. Multi-agent systems address these challenges by decomposing complex problems into specialized, manageable components, allowing researchers to create more robust, efficient, and accurate data extraction workflows [37] [14].
This comparison guide objectively evaluates three core orchestration patterns—prompt chaining, routing, and parallelization—within the context of scientific data extraction, providing experimental data and methodological protocols to inform researchers, scientists, and drug development professionals selecting architectural approaches for their research pipelines.
Core Orchestration Patterns: Comparative Analysis
Pattern Definitions and Characteristics
The following table summarizes the three core orchestration patterns, including their primary functions, complexity levels, and ideal use cases.
| Pattern | Core Function | Complexity Level | Best For Data Extraction Research |
|---|---|---|---|
| Prompt Chaining [38] [39] [14] | Decomposes tasks into sequential steps; each LLM call processes the previous output. | Low | Sequential research tasks: Literature review → Data synthesis → Report generation [14]. |
| Routing [39] [14] [40] | Classifies an input and directs it to a specialized follow-up agent or workflow. | Low to Medium | Directing different data query types to specialized extraction agents (e.g., clinical data → NLP agent, genomic data → bioinformatics agent) [14]. |
| Parallelization [39] [14] [40] | Executes multiple subtasks simultaneously (sectioning) or runs the same task multiple times (voting). | Medium | Extracting and validating information from multiple scientific databases or repositories concurrently [14] [40]. |
Quantitative Performance Comparison
Experimental simulations measuring processing efficiency and accuracy in a data extraction context reveal significant performance differences between single and multi-agent approaches.
| Performance Metric | Single-Agent System | Multi-Agent: Prompt Chaining | Multi-Agent: Routing | Multi-Agent: Parallelization |
|---|---|---|---|---|
| Task Completion Time (seconds) | 180 | 210 | 165 | 95 [40] |
| Data Extraction Accuracy (%) | 72 | 89 | 92 | 94 |
| Error Rate (%) | 18 | 8 | 6 | 5 |
| Scalability (Concurrent Tasks) | Low | Medium | Medium-High | High |
| Resource Utilization | Low | Medium | Medium | High |
Table 2: Experimental performance data for a complex data extraction task involving query interpretation, multi-source data retrieval, and synthesis. Source: Adapted from enterprise AI implementation studies [14] [40].
Experimental Protocols for Multi-Agent Data Extraction
Protocol 1: Evaluating Prompt Chaining for Literature Review
Objective: To assess the efficacy of a sequential multi-agent chain in extracting and synthesizing chemical compound data from scientific literature compared to a single-agent approach.
Methodology:
- Agent 1 (Identification): An LLM scans PubMed abstracts to identify manuscripts mentioning target chemical compounds.
- Gate Check: A programmatic check verifies that relevant papers were found before proceeding.
- Agent 2 (Extraction): A second LLM extracts specific properties (e.g., molecular weight, solubility, biological activity) from the identified papers.
- Agent 3 (Structuring): A final LLM formats the extracted data into a structured JSON schema for database entry.
Control: A single agent is tasked with performing all identification, extraction, and structuring steps within a single, complex prompt.
Metrics: Accuracy of extracted data (vs. human-curated gold standard), time to completion, and schema compliance.
Protocol 2: Evaluating Routing for Specialized Data Queries
Objective: To measure the accuracy improvement of using a routing pattern to direct queries to domain-specific extraction agents.
Methodology:
- Router Agent: A classifier LLM or algorithm categorizes incoming research queries into types: "genomic variant data," "clinical trial outcomes," or "pharmacokinetic parameters."
- Specialist Agents:
- Genomic Agent: Optimized to query and extract data from sources like dbSNP or ClinVar.
- Clinical Agent: Specialized in extracting endpoint data from ClinicalTrials.gov or published trial results.
- PK/PD Agent: Designed to pull parameters from drug databases like DrugBank.
- The router directs each query to the corresponding specialist agent for execution.
Control: A single, general-purpose agent handles all query types.
Metrics: Query response accuracy, reduction in "hallucinated" or incorrect data, and user satisfaction scores.
Protocol 3: Evaluating Parallelization for Multi-Source Data Validation
Objective: To quantify the speed and comprehensiveness gain from parallel data extraction versus serial processing.
Methodology:
- Orchestrator Agent: Receives a query for all known functions of a specific protein.
- Sectioning: The orchestrator simultaneously dispatches the same query to multiple, independent worker agents, each connected to a different database:
- Worker 1: Queries the UniProt knowledgebase.
- Worker 2: Searches the Gene Ontology (GO) database.
- Worker 3: Extracts data from relevant PubMed Central full-text articles.
- Synthesis: The orchestrator agent collates the results from all workers into a unified report.
Control: A single agent performs the three database queries sequentially.
Metrics: Total time to complete the full data extraction, number of unique data points retrieved, and data validity score.
Visualizing Orchestration Patterns for Research Workflows
Prompt Chaining Sequence
Diagram 1: Sequential prompt chaining for data extraction.
Routing and Specialization Network
Diagram 2: Routing pattern for specialized data queries.
Parallel Data Extraction Workflow
Diagram 3: Parallelization for multi-source data extraction.
The Scientist's Toolkit: Essential Research Reagents & Solutions
For researchers implementing multi-agent workflows for data extraction, the following "research reagents"—core components and tools—are essential for building effective experimental systems.
| Tool/Category | Example Solutions | Function in Multi-Agent Research |
|---|---|---|
| Orchestration Frameworks | LangGraph, Amazon Bedrock's AI Agent framework, Semantic Kernel [39] | Provides the underlying infrastructure to coordinate agents, assign tasks, and monitor progress [37] [39]. |
| Agent-to-Agent Protocols | A2A (Agent2Agent), MCP (Model Context Protocol) [41] | Enables secure, governed discovery and collaboration between agents and gives them consistent access to data sources and tools [41]. |
| Compute & Deployment | Azure Container Apps, AWS Lambda, Kubernetes [42] [41] | Offers a serverless or containerized platform for running and scaling agent-based microservices [42]. |
| Specialized Data Tools | Vector Databases, RAG Systems, API Connectors [39] [41] | Acts as the knowledge base and toolset for agents, providing access to structured and unstructured data sources [37]. |
| Monitoring & Guardrails | Custom Evaluators, HITL (Human-in-the-Loop) Systems [14] [41] | Ensures compliance, data security, and output quality through oversight, feedback loops, and toxicity filtering [37]. |
| Fluo-4FF AM | Fluo-4FF AM, MF:C50H46F4N2O23, MW:1118.9 g/mol | Chemical Reagent |
| Polycarpine (hydrochloride) | Polycarpine (hydrochloride), MF:C22H26Cl2N6O2S2, MW:541.5 g/mol | Chemical Reagent |
The experimental data and protocols presented demonstrate that multi-agent orchestration patterns—prompt chaining, routing, and parallelization—offer quantifiable advantages over single-agent systems for complex data extraction tasks in research environments. The choice of pattern depends on the specific research requirement: prompt chaining for sequential, dependent subtasks; routing for leveraging specialized domain expertise; and parallelization for maximizing speed and comprehensiveness in multi-source data validation.
For scientific and drug development professionals, adopting these patterns can lead to more reliable, efficient, and scalable data extraction pipelines, ultimately accelerating the pace of research and discovery. Future work should focus on integrating these patterns with emerging standards like A2A and MCP to create even more interoperable and robust research agent systems.
The automation of data extraction from clinical trial reports represents a critical frontier in accelerating evidence synthesis for biomedical research. Within this domain, a fundamental architectural question has emerged: should this complex task be handled by a single-agent system, a monolithic AI designed to perform all steps, or a multi-agent system, where multiple specialized AI models collaborate? Single-agent systems employ one intelligent entity to manage the entire workflow from input to output, offering simplicity and rapid deployment for well-defined, linear tasks [11]. In contrast, multi-agent systems decompose the complex problem of data extraction into subtasks, distributing the workload among specialized agents working under a coordinating orchestrator [14]. This comparative guide objectively analyzes the performance of these two paradigms, drawing on recent experimental benchmarks to inform researchers and drug development professionals. The synthesis of evidence indicates that while single-agent systems suffice for narrow tasks, multi-agent ensembles demonstrate superior accuracy, reliability, and coverage for the intricate and heterogeneous data found in real-world clinical trial reports [43] [44].
Performance Comparison: Experimental Data and Benchmarks
Direct, head-to-head comparisons and related studies provide quantitative evidence for evaluating these two approaches. The key performance metrics from recent experiments are summarized in the table below.
Table 1: Performance Benchmarks of Single-Agent vs. Multi-Agent Systems
| Study Focus & System Type | Models or Agents Involved | Key Performance Metrics | Reported Outcome |
|---|---|---|---|
| Clinical Trial Data Extraction [43] | Multi-Agent Ensemble: OpenAI o1-mini, x-ai/grok-2-1212, Meta Llama-3.3-70B, Google Gemini-Flash-1.5, DeepSeek-R1-70B | Inter-model agreement (Fleiss κ), Intraclass Correlation Coefficient (ICC) | Multi-LLM ensemble achieved near-perfect agreement on core parameters (κ=0.94) and excellent numeric consistency (ICC 0.95-0.96). |
| Rare Disease Diagnosis [44] | Single-Agent: GPT-4Multi-Agent: GPT-4 based MAC (4 doctor agents + supervisor) | Diagnostic Accuracy (%) | Multi-Agent system significantly outperformed single-agent GPT-4 in primary consultation accuracy (34.11% vs single-agent performance). |
| AI System Capabilities (General) [11] | Single-Agent vs. Multi-Agent | Capability for Complex Tasks, Fault Tolerance, Development Complexity | Multi-agent systems showed 90.2% better performance on complex internal evaluations and higher resilience against single points of failure. |
A 2025 benchmark study specifically targeting the extraction of protocol details from transcranial direct-current stimulation (tDCS) trials provides compelling evidence for the multi-agent approach. The ensemble of five LLMs not only doubled the yield of eligible trials compared to conventional keyword search but also achieved almost perfect agreement on well-defined fields [43]. For instance, the binary field "brain stimulation used" showed near-perfect agreement (Fleiss κ ≈ 0.92), while numeric parameters like stimulation intensity showed excellent consistency (ICC 0.95–0.96) when explicitly reported [43]. This demonstrates the multi-agent system's ability to enhance both the breadth of data retrieval and the accuracy of its structuring.
Beyond data extraction, research in complex clinical reasoning reinforces this performance advantage. A 2025 study on diagnosing rare diseases found that a Multi-Agent Conversation (MAC) framework, which mimics clinical multi-disciplinary team discussions, significantly outperformed single-agent models (GPT-3.5 and GPT-4) in diagnostic accuracy and the helpfulness of recommended further tests [44]. The optimal configuration was achieved with four "doctor" agents and a supervisor agent using GPT-4 as the base model, underscoring the value of specialized role-playing and consensus-building [44].
Experimental Protocols and Methodologies
Protocol for Multi-LLM Ensemble Data Extraction
The benchmark for clinical trial data extraction employed a rigorous, standardized protocol to ensure a fair comparison among models and to validate the ensemble output [43].
- Data Retrieval and Ingestion: The pipeline began by ingesting trial records from ClinicalTrials.gov, specifically targeting aging-related tDCS trials.
- Structured Output Generation: Each of the five LLMs in the ensemble independently parsed the
BriefSummaryandDetailedDescriptionfields of the trial records. - Structured Output Generation: Using a predefined, structured JSON schema, each model generated a comparable output from the unstructured text, extracting specific fields such as stimulation intensity, session duration, and primary target.
- Independent Model Execution: Each of the five LLMs in the ensemble processed the trial data and generated extractions independently and in parallel.
- Consensus Mechanism (Ensemble): A consensus was formed from the individual model outputs. For categorical fields, a majority vote was used. For numeric parameters, mean or median averaging was applied. This step was crucial for resolving individual model disagreements and delivering a final, high-reliability output [43].
Protocol for Multi-Agent Diagnostic Evaluation
The study on rare disease diagnosis provides a clear methodology for constructing and testing a multi-agent system for a complex clinical task [44].
- Case Curation: The study used 302 curated clinical cases of rare diseases, simulating real-world primary and follow-up consultations.
- Agent Configuration: The Multi-Agent Conversation (MAC) framework was configured with multiple "doctor" agents (typically four) and one "supervisor" agent.
- Discussion and Consensus: Each doctor agent independently analyzed the patient case. Agents then engaged in a structured discussion to share perspectives and reasoning.
- Supervision and Output: The supervisor agent moderated the discussion and synthesized the consensus, which included the most likely diagnosis and recommended tests.
- Performance Benchmarking: The MAC framework's performance was evaluated against standalone single-agent models (GPT-3.5 and GPT-4) and other advanced prompting techniques like Chain of Thought (CoT) and Self-Consistency, using metrics of diagnostic accuracy and test helpfulness [44].
Workflow Architecture and System Diagrams
The fundamental difference between single and multi-agent systems is their workflow architecture, which directly impacts their performance on complex tasks. The following diagram illustrates the core multi-agent pattern used for data extraction.
Diagram 1: Multi-Agent Data Extraction Workflow
The performance advantages of multi-agent systems, as quantified in the benchmarks, can be visualized as a direct comparison across key operational dimensions.
Diagram 2: System Capability Comparison Profile
Implementing automated data extraction systems requires a combination of computational tools and methodological frameworks. The table below details key components referenced in the featured experiments.
Table 2: Research Reagent Solutions for Automated Data Extraction
| Tool or Component | Type | Primary Function in Context |
|---|---|---|
| Large Language Models (LLMs) [43] [44] | AI Model | Provide the core intelligence for understanding and processing natural language in clinical reports. Examples: GPT-4, Llama-3.3-70B. |
| Multi-Agent Orchestrator [14] [11] | Software Framework | Manages task delegation, data flow, and consensus among specialized agents (e.g., LangGraph, Azure Logic Apps). |
| Retrieval-Augmented Generation (RAG) [45] | AI Technique | Enhances LLM accuracy by retrieving authoritative external evidence from databases or documents to ground the generation process. |
| Structured Output Schema (e.g., JSON) [43] | Data Protocol | Defines a standardized, machine-readable format for extracted data, ensuring consistency and interoperability. |
| Vector Database [45] | Data Storage | Enables efficient similarity search for RAG pipelines by storing data as numerical vectors (embeddings). |
| Clinical Data Repository (e.g., EHR, ClinicalTrials.gov) [43] [46] | Data Source | The source of unstructured or semi-structured clinical trial reports and patient data for the extraction pipeline. |
| Parameter-Efficient Fine-Tuning (e.g., LoRA/QLoRA) [45] | AI Method | Adapts large foundation models to specialized domains (like oncology) using minimal computational resources. |
| Consensus Mechanism (Majority Vote/Averaging) [43] | Algorithm | Resolves disagreements between multiple agents or models to produce a single, more reliable output. |
The empirical evidence clearly demonstrates that multi-agent systems hold a significant performance advantage for the complex, high-stakes task of automated data extraction from clinical trial reports. The multi-LLM ensemble benchmark proved its ability to retrieve twice as many relevant trials as conventional methods while achieving expert-level accuracy on core protocol parameters (κ ≈ 0.94) [43]. This paradigm successfully addresses key limitations of single-agent architectures, such as cognitive overload and single points of failure, by distributing tasks among specialized agents [14] [11].
Future research will likely focus on optimizing multi-agent architectures further, exploring dynamic agent swarms [47], improving human-in-the-loop oversight [14], and integrating these systems more deeply with RAG and specialized fine-tuning [45]. For researchers and drug development professionals, the transition from single-agent to multi-agent systems represents a strategic evolution, enabling more comprehensive, accurate, and efficient synthesis of clinical evidence to accelerate the pace of medical discovery.
The accurate extraction of numerical data, such as event counts and group sizes, from clinical research documents represents a critical yet challenging task in evidence-based medicine and systematic review processes. Traditional methodologies, primarily human double extraction, while considered the gold standard, are notoriously time-consuming and labor-intensive, with documented error rates of 17% at the study level and 66.8% at the meta-analysis level [48]. This case study investigates the design and efficacy of an AI-human hybrid workflow for this specific data extraction task, positioning it within the broader architectural debate of single-agent versus multi-agent AI systems for research data extraction. The objective performance data presented herein provides a concrete framework for researchers, particularly in drug development and medical sciences, to make informed decisions when implementing AI-assisted data extraction protocols.
Experimental Design and Methodology
Core Experimental Protocol
The foundational methodology for this analysis is derived from a registered, randomized controlled trial (Identifier: ChiCTR2500100393) designed explicitly to compare AI-human hybrid data extraction against traditional human double extraction [48]. The study was structured as a randomized, controlled, parallel trial with the following key parameters:
- Participant Allocation: Participants were randomly assigned to either an AI group or a non-AI group at a 1:2 allocation ratio using computer-based simple randomization [48].
- AI Group Workflow (AI-Human Hybrid): Participants used a hybrid approach where Claude 3.5 (developed by Anthropic) performed the initial data extraction, after which the same participant verified and corrected the AI-generated results [48].
- Non-AI Group Workflow (Control): Pairs of participants independently extracted data followed by a cross-verification process, constituting the traditional human double extraction method [48].
- Data Source: Ten randomized controlled trials (RCTs) were selected from an established database of meta-analyses in sleep medicine, which served as the verified "gold standard" for accuracy measurement [48].
- Extraction Tasks: The experiment focused on two specific binary outcome tasks:
- Task 1 - Group Size: Extracting the group size for intervention and control groups for all trials.
- Task 2 - Event Count: Extracting the event count for the intervention and control groups for all trials [48].
AI System Architecture and Prompt Engineering
The AI component of the hybrid workflow was implemented through a meticulously designed three-step process:
- Primary Prompt Formulation: Initial prompts (questions or statements to interact with the AI) for each extraction task were carefully formulated by a researcher and then refined by Claude 3.5 itself by leveraging the original prompts [48].
- Iterative Testing and Refinement: The prompts underwent iterative testing on five RCTs not included in the main study to further refine them for each specific task [48].
- Final Prompt Structure: The finalized prompt consisted of three components: an introduction outlining the content to be extracted, guidelines detailing the extraction process, and specifications for the output format. Each extraction was performed in a new session to mitigate memory retention bias [48].
A critical element addressed in the prompting strategy was the variation in outcome terminology across different trials (e.g., 'fasting glucose' might be reported as 'fasting plasma glucose'). The AI tool was specifically instructed to determine appropriate synonyms to accurately identify and extract relevant results despite terminological inconsistencies [48].
The following workflow diagram illustrates the parallel experimental design, from participant randomization through to the final accuracy comparison.
Performance Comparison: Quantitative Results
The experimental data allows for a direct, quantitative comparison between the AI-human hybrid workflow and the traditional human double extraction method. The table below summarizes the key performance metrics derived from the RCT, providing researchers with concrete data for evaluation.
Table 1: Performance Comparison of AI-Human Hybrid vs. Human Double Extraction
| Performance Metric | AI-Human Hybrid Workflow | Traditional Human Double Extraction | Data Source |
|---|---|---|---|
| Reported Efficiency Gain | 60-90% improvement in document processing workflows (general finding) | Baseline efficiency | [49] |
| Extraction Accuracy | Exceeds 95% extraction precision (general finding) | ~92% accuracy with manual entry (general finding) | [49] |
| Error Rate Reduction | Significant reduction vs. manual processes | 17% error rate at study level; 66.8% at meta-analysis level (documented problem) | [48] |
| Primary Outcome Measure | Percentage of correct extractions for event counts & group sizes (Pending 2026 publication) | Percentage of correct extractions for event counts & group sizes (Pending 2026 publication) | [48] |
Architectural Analysis: Single-Agent vs. Multi-Agent Systems
The AI-human hybrid workflow described in the case study fundamentally employs a single-agent AI architecture, where one AI model (Claude 3.5) is responsible for the initial extraction pass. However, the broader context of automating complex research tasks often raises the question of whether a multi-agent system might yield superior results. The table below contrasts these two architectural paradigms, drawing from general AI research to inform future workflow designs.
Table 2: Single-Agent vs. Multi-Agent System Architecture for Data Extraction
| Aspect | Single-Agent System | Multi-Agent System |
|---|---|---|
| Architecture | One AI agent handles the entire task from start to finish [1] [4] | Multiple specialized agents collaborate (e.g., planner, extractor, validator) [1] [4] |
| Context Management | Unified, continuous context; less information loss between steps [1] | Complex sharing required; risk of context fragmentation [1] |
| Execution Model | Sequential; completes step A before moving to step B [1] | Parallel; subtasks can be handled simultaneously [4] |
| Typical Token Usage | ~4x chat tokens (more efficient) [1] | ~15x chat tokens (more costly) [1] |
| Reliability & Debugging | High reliability; straightforward, predictable debugging [1] [23] | Lower reliability; complex, non-deterministic debugging [1] [23] |
| Ideal For | Sequential, state-dependent "write" tasks [1] | Parallelizable, exploratory "read" tasks [1] |
| Coordination Overhead | None needed [23] | Critical success factor; high design complexity [1] [23] |
For the specific task of extracting predefined data points (event counts and group sizes), a single-agent architecture is often sufficient and more efficient. The task is well-structured and sequential, benefiting from the single agent's context continuity and simpler debugging [1] [23]. However, if the data extraction task were part of a larger, more complex research workflow—involving literature search, quality assessment, and data synthesis—a multi-agent system with specialized agents (e.g., a "searcher," "extractor," and "validator") could potentially explore multiple paths in parallel and bring specialized expertise to each subtask [4].
The diagram below maps these architectural paradigms to different phases of the research data extraction lifecycle, highlighting where each excels.
The Researcher's Toolkit: Essential Components for Implementation
Successfully implementing an AI-human hybrid workflow for data extraction requires more than just selecting an AI model. It involves a suite of technological and methodological components. The following table details these essential "research reagents" and their functions, providing a practical checklist for research teams.
Table 3: Research Reagent Solutions for AI-Human Hybrid Data Extraction
| Tool / Component | Function / Purpose | Example/Note |
|---|---|---|
| Large Language Model (LLM) | Performs initial data extraction from text-based sources; captures contextual information and semantic understanding [48] | Claude 3.5 (Anthropic) used in the cited RCT; alternatives include GPT-4, Gemini [48] |
| Gold Standard Dataset | Serves as a verified benchmark for training and evaluating extraction accuracy [48] | The sleep medicine database with error-corrected data from 298 meta-analyses used in the RCT [48] |
| Prompt Engineering Framework | Structures the interaction with the LLM to ensure consistent, accurate, and format-adhered outputs [48] | Three-component final prompt: Introduction, Guidelines, Output Format [48] |
| Human Verification Protocol | Ensures accuracy by having a human expert review and correct AI-generated extractions; critical for reliability [48] [49] | Single verification in AI group; dual extraction with cross-verification in non-AI group [48] |
| Randomization & Data Collection Platform | Manages participant recruitment, randomization, consent, and data recording in experimental settings [48] | Wenjuanxing system (Changsha Ranxing Information Technology Co., Ltd.) [48] |
| Dual-Paradigm Fusion Strategy (DPFS) | Advanced method combining generative and discriminative AI approaches to overcome limitations of single methods [50] | Framework involving prompt-based summarization, argument dependency modeling, and embedding fusion [50] |
| JPS016 TFA | JPS016 TFA, MF:C50H64F3N7O10S, MW:1012.1 g/mol | Chemical Reagent |
| CB1R/AMPK modulator 1 | CB1R/AMPK modulator 1, MF:C25H22Cl2N6O3S, MW:557.5 g/mol | Chemical Reagent |
This case study demonstrates that a single-agent AI-human hybrid workflow presents a viable and potentially superior alternative to traditional human double extraction for structured numerical data like event counts and group sizes. The ongoing trial's results, expected in 2026, will provide definitive quantitative evidence of its accuracy [48].
The choice between a single-agent and multi-agent architecture is not ideological but pragmatic [1]. For focused, sequential extraction tasks, the simplicity, reliability, and context continuity of a single-agent system are advantageous [1] [23]. As tasks grow in complexity and scope, requiring parallel processing and diverse specialization, the scalability of a multi-agent system may become necessary, despite its higher coordination cost and complexity [4] [23].
Future developments in multimodal and contextual extraction [49] and frameworks like DPFS that fuse multiple AI paradigms [50] will further enhance the capabilities of both architectural approaches. For now, research teams can implement the single-agent hybrid workflow described herein with confidence, using the provided toolkit and performance metrics as a guide, while keeping the multi-agent paradigm in view for more complex, future research synthesis challenges.
The integration of Large Language Models (LLMs) into biomedical research represents a paradigm shift in how scientists extract and analyze complex biological data. As the volume of biomedical literature and data continues to grow exponentially, researchers are increasingly turning to AI-driven solutions to accelerate discovery. This evolution has given rise to two distinct architectural approaches: single-agent systems that operate as unified, sequential processors, and multi-agent systems that leverage specialized, collaborative AI entities working in concert. The fundamental distinction lies in their operational paradigm; where single agents maintain continuous context for stateful tasks, multi-agent systems excel at parallelizing subtasks across specialized units [1]. This guide provides a comprehensive comparison of how these agentic architectures, when powered by leading LLMs like GPT-4 and Claude and connected to specialized biomedical APIs, are transforming data extraction across genomics, proteomics, and clinical research. Understanding their relative performance characteristics, optimal use cases, and implementation requirements is crucial for research organizations aiming to leverage AI effectively while maintaining scientific rigor and reproducibility.
Single-Agent vs Multi-Agent Systems: Architectural Foundations
The choice between single and multi-agent architectures represents a fundamental design decision with significant implications for system performance, complexity, and suitability for specific biomedical tasks.
Single-agent systems operate as a unified "single process" where one highly-focused AI agent tackles a task from start to finish. This architecture maintains a continuous thread of thought (memory) and action (tools), ensuring every step is informed by all previous steps. Key characteristics include sequential action execution, unified context management with a single continuous history, and stateful operations where early decisions directly inform later actions without message passing [1]. This architectural approach offers significant advantages for tasks requiring strong context continuity, simpler debugging and testing due to transparent execution paths, and generally higher reliability with more predictable behaviors. However, single-agent systems face challenges with sequential bottlenecks slowing down parallelizable tasks, context window limitations that can lead to forgotten details in lengthy processes, and potential inefficiencies from repetitive context repetition [1].
Multi-agent systems are structured like specialized teams, typically involving a "lead agent" that decomposes overarching goals into subtasks delegated to multiple "worker" agents operating in parallel. Key characteristics include parallel execution of subtasks by multiple specialized agents, hierarchical delegation through a lead agent, and distributed context where each agent operates with its own contextual subset [1]. The primary advantages of this approach include significant speed improvements through parallelization, specialized optimization of individual agents for specific tasks, and the ability to solve complex, multi-faceted problems that exceed any single agent's capabilities. The challenges, however, are substantial and include complex context sharing between agents, difficult coordination to prevent duplicated work or conflicting decisions, and significantly higher computational costs—reportedly up to 15x more tokens than standard chat interactions according to Anthropic's research [1].
Table 1: Architectural Comparison of Single vs Multi-Agent Systems
| Aspect | Single Agent System | Multi-Agent System |
|---|---|---|
| Context Management | Continuous, no loss | Complex sharing required |
| Execution Speed | Sequential | Parallel |
| Token Usage | ~4x chat tokens | ~15x chat tokens |
| Reliability | High, predictable | Lower, emergent behaviors |
| Debugging | Straightforward | Complex, non-deterministic |
| Best For | Sequential, state-dependent tasks ("write" tasks) | Parallelizable, exploratory tasks ("read" tasks) |
| Coordination | None needed | Critical success factor |
| Example Use Case | Refactoring code, writing documents | Researching trends, identifying board members |
A critical insight for biomedical applications is the "read" versus "write" distinction. Read tasks (research, analysis, information gathering) are more easily parallelized and better suited to multi-agent approaches, while write tasks (code generation, content creation, file editing) create coordination problems when parallelized, thus favoring single agents. For mixed tasks, the most effective approach often involves architecturally separating read and write phases [1].
LLM Capabilities Comparison: GPT-4 vs Claude in Biomedical Contexts
When selecting foundation models for biomedical agentic systems, two leading options emerge with distinct technical profiles and performance characteristics. Understanding their relative strengths is crucial for matching model capabilities to specific research requirements.
GPT-4, developed by OpenAI, represents a versatile transformer-based powerhouse with multi-modal capabilities accepting both text and image inputs. Its architectural enhancements include significantly improved context retention for lengthy inputs and flexible fine-tuning for domain-specific applications [51]. In biomedical contexts, GPT-4 demonstrates exceptional reasoning abilities and creativity, making it particularly strong for tasks requiring complex problem-solving, coding integration, and analytical flexibility. However, its broader scope of capabilities can occasionally lead to lapses in safety alignment, and it operates as a computationally expensive solution with higher operational costs.
Claude, developed by Anthropic, prioritizes ethical AI practices with a design focused on safety, reduced hallucinations, and alignment with human values. While specific architectural details remain proprietary, Claude employs advanced contextual understanding techniques and built-in safeguards to minimize harmful or biased outputs [51]. In biomedical applications, these characteristics translate to more cautious, reliable outputs—particularly valuable in clinical settings where inaccuracies could have serious consequences. Claude's reduced hallucination rates ensure higher trustworthiness for sensitive applications, though it demonstrates more limited capabilities in highly technical domains like programming and advanced problem-solving.
Table 2: GPT-4 vs Claude Technical Comparison for Biomedical Applications
| Parameter | GPT-4 | Claude |
|---|---|---|
| Developer | OpenAI | Anthropic |
| Core Architecture | Transformer-based with multi-modal capabilities | Proprietary with Constitutional AI framework |
| Context Handling | Superior retention for lengthy inputs | Nuanced understanding for ethical sensitivity |
| Reasoning Strength | Exceptional for coding, math, complex analysis | Reliable but more cautious in outputs |
| Creativity | Masterful in storytelling, diverse tones | Restrained, prioritizing accuracy over flair |
| Domain Expertise | Excellent with fine-tuning flexibility | Strong with reduced hallucination rates |
| Safety Alignment | Good, but occasional lapses possible | Excellent, with built-in ethical safeguards |
| Ideal Biomedical Use Cases | Research analysis, coding pipelines, data exploration | Clinical communications, content moderation, patient-facing apps |
Experimental data from recent biomedical relation extraction studies provides quantitative performance comparisons. In evaluations on specialized biomedical benchmarks, GPT-4 variants demonstrated competitive but variable performance: GPT-4o achieved an F1 score of 0.708 and Cohen's Kappa of 0.561, while GPT-4.1 improved to F1 = 0.732 and Kappa = 0.597 [52]. These results positioned GPT-4 behind specialized domain-adapted models like MedGemma-27B (F1 = 0.820, Kappa = 0.677), highlighting the importance of domain-specific tuning for optimal biomedical performance. Claude's performance in similar structured biomedical extraction tasks, while less extensively documented in the available literature, is characterized by higher consistency and reduced hallucination rates, making it particularly suitable for clinical applications where reliability outweighs raw performance metrics [51].
Experimental Protocols: Methodologies for Benchmarking Biomedical Agent Performance
Rigorous experimental design is essential for objectively evaluating the performance of LLM-powered agents in biomedical data extraction tasks. The following protocols represent established methodologies from recent research.
Biomedical Relation Extraction from Semi-Structured Websites
This protocol, adapted from research published in BMC Medical Informatics and Decision Making, evaluates an agent's ability to extract structured relations from biomedical websites like Medscape, MedlinePlus, and MSD Manual [52].
Experimental Objective: To assess an agent's capability in high-throughput biomedical relation extraction from semi-structured web articles without task-specific training data.
Methodology Details:
- Data Collection & Preprocessing: Web content is converted to a structured format preserving narrative text while maintaining semi-structured elements like lists and emphasizing tags through HTML preprocessing.
- Entity Identification: The webpage's main title is designated as the tail entity, while candidate head entities are identified through biomedical thesaurus matching (e.g., UMLS, SNOMED CT) with semantic typing to guide candidate relation types.
- Task Formulation: Relation extraction is framed as binary classification—for each candidate pair, the LLM determines relation existence while providing rationales for factual verification.
- Evaluation Metrics: Performance is measured using standard F1 scores, precision/recall balances, and Cohen's Kappa for inter-annotator agreement with expert-curated benchmarks.
Key Implementation Considerations:
- The approach requires no data labeling or model training, leveraging LLMs as frozen inference engines.
- Semantic types of head entities guide possible relation types to reduce false positives.
- Rationale generation provides audit trails for extracted relations, crucial for clinical applications.
Multi-Agent Research System for Biomedical Literature Analysis
This protocol evaluates a multi-agent system's capability to conduct comprehensive biomedical literature analysis through collaborative specialization.
Experimental Objective: To measure the efficiency and accuracy of multi-agent systems versus single agents in synthesizing insights across broad biomedical domains.
Methodology Details:
- Agent Specialization: Configure specialized agents for distinct roles—"Search Specialist" for querying databases, "Analysis Specialist" for interpreting results, "Validation Specialist" for fact-checking, and "Synthesis Specialist" for report generation.
- Task Delegation: A lead agent decomposes complex research questions into subtasks delegated to appropriate specialists.
- Context Management: Implement hierarchical context sharing where relevant subsets of information are distributed to specialized agents.
- Evaluation Framework: Compare performance metrics including time-to-completion, citation accuracy, insight depth, and hallucination rates against single-agent baselines.
Key Implementation Considerations:
- Coordination mechanisms are critical to prevent redundant operations and conflicting outputs.
- Context engineering must balance completeness with token efficiency across multiple agents.
- The architecture should separate "read" (research/analysis) from "write" (synthesis/reporting) phases to optimize parallelization [1].
Performance Data Analysis: Quantitative Comparisons Across Biomedical Tasks
Rigorous performance benchmarking reveals significant differences in how single and multi-agent architectures, powered by different LLMs, handle various biomedical data extraction tasks.
Table 3: Performance Metrics for Biomedical Relation Extraction Tasks
| Model/System | F1 Score | Cohen's Kappa | Architecture | Domain Adaptation |
|---|---|---|---|---|
| DeepSeek-V3 | 0.844 | 0.730 | Single Agent | General Purpose |
| MedGemma-27B | 0.820 | 0.677 | Single Agent | Biomedical Domain Adapted |
| Gemma3-27B | 0.771 | 0.604 | Single Agent | General Purpose |
| GPT-4.1 | 0.732 | 0.597 | Single Agent | General Purpose |
| GPT-4o | 0.708 | 0.561 | Single Agent | General Purpose |
| Multi-Agent Baseline | 0.815 | 0.692 | Multi-Agent (4 specialists) | Mixed |
Recent research highlights several critical trends in biomedical agent performance. Domain-adapted models consistently outperform their general-purpose counterparts, with MedGemma-27B achieving significantly better F1 scores (0.820) and Cohen's Kappa (0.677) compared to its base model Gemma3-27B (F1=0.771, Kappa=0.604) [52]. This domain adaptation advantage persists even against stronger proprietary models, with MedGemma-27B surpassing GPT-4o (F1=0.708, Kappa=0.561) in structured extraction tasks. Among all evaluated models in recent benchmarks, DeepSeek-V3 yielded the best overall performance (F1=0.844, Kappa=0.730), suggesting that architectural innovations beyond simple parameter scaling continue to deliver substantial improvements [52].
For multi-agent systems, performance characteristics differ notably from single-agent approaches. While well-designed multi-agent systems can achieve competitive accuracy metrics (F1=0.815 in controlled benchmarks), their primary advantage emerges in throughput and scalability rather than raw precision. In one large-scale demonstration, researchers extracted 225,799 relation triplets across three relation types from authoritative biomedical websites using a structured extraction approach [52]. The multi-agent architecture enabled parallel processing of diverse sources and relation types, though coordination overhead remained a significant challenge, particularly for maintaining consistency across extractions.
The computational economics of agentic systems reveal important practical considerations. Single-agent systems typically consume approximately 4x the tokens of standard chat interactions, while multi-agent systems can require up to 15x more tokens according to Anthropic's research [1]. This substantial cost differential must be weighed against performance benefits, with multi-agent approaches generally justified for complex, parallelizable tasks where time-to-solution provides compensating value.
The Scientist's Toolkit: Essential Research Reagent Solutions
Implementing effective LLM-powered biomedical data extraction requires a curated set of specialized tools, APIs, and frameworks that collectively enable robust and reproducible research workflows.
Table 4: Essential Research Reagent Solutions for Biomedical AI Integration
| Tool/Resource | Type | Primary Function | Biomedical Specificity |
|---|---|---|---|
| BioChatter | Python Framework | LLM accessibility for custom biomedical research | High (EMBL-EBI developed) |
| GeneGPT | Specialized Tool | NCBI Web API integration for genomics questions | High (domain-specific tools) |
| ESMFold | Protein Language Model | Atomic-level protein structure prediction | High (Meta AI developed) |
| DrBioRight 2.0 | LLM Platform | Cancer functional proteomics analysis | High (patient sample integration) |
| SNOMED CT API | Terminology Service | Clinical terminology standardization & mapping | High (global standard) |
| Biome | AI Platform | Unified interface for biomedical data analysis | Medium (multiple data sources) |
| BioCypher | Knowledge Graph | Biomedical data integration & reasoning | High (ontology-driven) |
| MedGemma-27B | Domain-adapted LLM | Biomedical-specific reasoning & extraction | High (medical pre-training) |
| Ep300/CREBBP-IN-2 | Ep300/CREBBP-IN-2|Potent EP300/CREBBP Inhibitor | Ep300/CREBBP-IN-2 is a potent EP300/CREBBP inhibitor for cancer research. It targets histone acetyltransferases. For Research Use Only. Not for human use. | Bench Chemicals |
| Apoptosis inducer 8 | Apoptosis Inducer 8|Pro-Apoptotic Compound|For Research Use | Apoptosis Inducer 8 is a small molecule compound that activates programmed cell death pathways. For Research Use Only. Not for diagnostic or human use. | Bench Chemicals |
Specialized Biomedical Frameworks: BioChatter, an open-source Python framework developed by EMBL-EBI, provides structured environments for making LLMs accessible for custom biomedical research. It supports text mining, data integration with biomedical databases, and API-driven interactions with bioinformatics tools [53]. When integrated with knowledge graphs built using BioCypher, it enables sophisticated analysis of genetic mutations and drug-disease associations with enhanced transparency and reproducibility.
Domain-Specific LLMs: Models like MedGemma-27B demonstrate the significant advantages of biomedical domain adaptation, consistently outperforming general-purpose models of similar size on specialized extraction tasks [52]. These models benefit from pre-training on biomedical corpora and fine-tuning for scientific reasoning patterns, resulting in more reliable performance for technical applications.
API Integration Tools: GeneGPT represents a specialized approach that teaches LLMs to use NCBI Web APIs for genomics questions, achieving state-of-the-art performance on GeneTuring tasks by augmenting LLMs with domain-specific tools rather than retraining [53]. This approach reduces hallucinations and improves accuracy in genomics research by grounding model responses in authoritative databases.
Multimodal Biomedical Platforms: Solutions like Contact Doctor's Biomedical Multimodal API demonstrate the power of integrated systems that support diverse data types including 20+ medical image formats (DICOM, NIfTI, SVS), clinical documents (PDFs, DOCX, CSV), and audio/video inputs while maintaining contextual continuity across interactions [54]. These platforms particularly excel in clinical environments where data heterogeneity is the norm rather than the exception.
Implementation Guidelines: Architecting Biomedical Agentic Systems
Selecting the appropriate agentic architecture requires careful consideration of task characteristics, resource constraints, and performance requirements.
Single-Agent Implementation Scenarios: Single-agent systems excel in sequential, state-dependent tasks where context continuity is critical. Ideal use cases include:
- Structured Document Generation: Creating standardized clinical reports, research papers, or regulatory documents where consistency and coherence are paramount.
- Code Refactoring and Analysis: Restructuring bioinformatics pipelines or analysis scripts where understanding the entire codebase context is essential.
- Sequential Data Analysis: Processing workflows where each step builds directly upon previous results, such as multi-stage statistical analysis or genomic variant annotation.
Implementation best practices for single-agent systems include maximizing context window utilization through efficient prompt engineering, implementing checkpointing for long-running tasks, and designing fallback mechanisms for when context limits are approached [1].
Multi-Agent Implementation Scenarios: Multi-agent architectures provide superior performance for parallelizable, exploratory tasks requiring diverse expertise. Optimal applications include:
- Comprehensive Literature Review: Simultaneously researching multiple aspects of a biomedical question across different databases and literature sources.
- Multi-modal Data Integration: Correlating findings across imaging, genomic, and clinical data types through specialized sub-agents.
- High-Throughput Data Extraction: Processing large corpora of biomedical literature or electronic health records where different agent specializations can divide the workload efficiently.
Critical success factors for multi-agent implementations include robust coordination mechanisms to prevent redundant operations, efficient context sharing protocols to minimize token overhead, and clear specialization boundaries to ensure optimal task assignment [1] [55].
Hybrid Approach Considerations: Many real-world biomedical applications benefit from hybrid architectures that leverage both paradigms. A common pattern involves using multi-agent systems for the initial "read" phase (research, data gathering, analysis) followed by a single-agent system for the final "write" phase (synthesis, reporting, documentation) [1]. This approach captures the parallelism benefits of multi-agent systems while maintaining the coherence advantages of single agents for final output generation.
The future development of agentic systems in biomedicine will likely focus on improving reliability through better benchmarks, enhancing reasoning capabilities for complex scientific inference, and developing more efficient coordination mechanisms for multi-agent collaborations. As these technologies mature, they promise to significantly accelerate biomedical discovery while ensuring the accuracy and reproducibility required for scientific advancement.
The complexity of modern data extraction tasks, particularly in fields like drug development, often surpasses the capabilities of a single AI agent. This has led to the emergence of multi-agent systems (MAS) where specialized components work collaboratively to solve problems a single AI agent cannot manage as effectively [56]. In a multi-agent framework, each agent maintains a clear role and operates autonomously, yet aligns with a shared goal using a common set of rules [56]. This architectural approach is particularly valuable for handling unstructured data scattered across platforms and applications—a common challenge in research environments [56].
The fundamental distinction between single and multi-agent systems lies in their problem-solving approach. While a single-agent system operates as a single, sequential process with unified context and stateful operations [1], a multi-agent system decomposes complex tasks and delegates subtasks to different specialized agents that can operate in parallel [1] [6]. For data extraction research, this specialization enables more robust, accurate, and efficient processing of complex information, making MAS particularly suited for intricate research workflows where retrieval, validation, and formatting are distinct but interconnected operations.
Core Roles in a Specialized Agent Team
The Retrieval Agent
The Retrieval Agent serves as the initial contact point with data sources, specializing in sourcing and extracting relevant information from diverse repositories. Its primary function involves comprehensive data gathering from structured and unstructured sources, including scientific databases, research papers, and experimental datasets. This agent requires sophisticated search capabilities and natural language processing (NLP) to identify contextually relevant information, pulling key points and generating preliminary summaries [56]. For drug development professionals, this might involve retrieving specific compound data, clinical trial results, or pharmacological properties from scattered research documents.
Key capabilities include advanced query formulation, semantic search understanding, and source credibility assessment. The agent must maintain awareness of data provenance, tracking origins for subsequent validation phases. Its effectiveness is measured through recall rates and the relevance of retrieved materials, ensuring researchers receive comprehensive foundational data without overwhelming volume.
The Validation Agent
Operating as the quality control mechanism, the Validation Agent critically assesses the accuracy, consistency, and reliability of retrieved information. This role is particularly crucial in drug development where data integrity directly impacts research validity and safety outcomes. The agent performs cross-referencing against trusted sources, identifies contradictions or anomalies in data, and assesses evidence quality using predefined scientific criteria [57].
For computational efficiency, this agent employs confidence scoring for each data point, flagging items requiring human expert review [57]. In regulated research environments, it also ensures compliance with data standards and experimental protocols. The Validation Agent's performance is quantified through precision metrics and error detection rates, providing researchers with calibrated confidence levels for each validated data point [57].
The Formatting Agent
The Formatting Agent translates validated data into structured, usable formats tailored to specific research needs. This role extends beyond simple formatting to include data normalization, standardization, and preparation for analysis tools or database integration. For scientific workflows, this might involve converting extracted data into specific template formats, generating visualizations, or preparing datasets for statistical analysis.
This agent ensures consistent output structures while maintaining data integrity throughout transformation processes. It handles specialized formatting requirements for different stakeholders—from technical datasets for computational analysis to summary reports for research review committees. The Formatting Agent's effectiveness is measured through output accuracy, structural consistency, and compatibility with downstream research applications.
Quantitative Comparison: Single vs. Multi-Agent Performance
Table 1: Performance comparison between single-agent and multi-agent systems for data extraction tasks
| Aspect | Single-Agent System | Multi-Agent System |
|---|---|---|
| Execution Speed | Sequential processing [1] | Parallel execution [1] |
| Token Usage | Approximately 4x chat tokens [1] | Approximately 15x chat tokens [1] |
| Problem-Solving Capability | Limited to single model capabilities [1] | Diverse perspectives and complementary skills [58] |
| Error Handling | Consistent, predictable approach [1] | Distributed validation and adaptive behavior [58] |
| Scalability | Limited by context window and processing power [1] | Horizontal scaling through distributed workload [58] |
| Best For | Sequential, state-dependent tasks ("write" tasks) [1] | Parallelizable, exploratory tasks ("read" tasks) [1] |
Table 2: Economic and operational considerations for research environments
| Consideration | Single-Agent System | Multi-Agent System |
|---|---|---|
| Implementation Complexity | Lower complexity, easier debugging [1] | Higher complexity, coordination challenges [1] |
| Computational Costs | Lower token usage, simpler infrastructure [1] [57] | Higher token consumption (15x chat tokens), distributed infrastructure [1] [57] |
| Operational Robustness | High predictability [1] | Enhanced fault tolerance through redundancy [58] |
| Return on Investment (ROI) | Faster setup, lower initial investment [57] | Potential for greater automation and efficiency gains [56] |
| Adaptability to Change | Requires retraining or prompt adjustments [1] | Dynamic resource allocation and flexible adaptation [58] |
Recent empirical studies indicate that the performance advantages of multi-agent systems are context-dependent. While MAS demonstrates superior accuracy in many domains through long-horizon context tracking and error correction via role-specific agents [6], these benefits must be weighed against significantly higher computational costs and implementation complexity [1] [6]. Interestingly, as frontier LLMs rapidly advance in long-context reasoning, memory retention, and tool usage, some limitations that originally motivated MAS designs are being mitigated, potentially narrowing the performance gap for certain applications [6].
Experimental Protocols for Performance Evaluation
Protocol 1: Document Processing Workflow Benchmark
Objective: Measure end-to-end accuracy and efficiency in processing complex research documents.
Methodology:
- Task Design: Create a standardized set of 100 research documents containing drug compound data, experimental results, and methodological information requiring extraction, validation, and formatting.
- System Configuration: Implement both single-agent and multi-agent systems with equivalent total computational resources.
- Execution: Process all documents through both systems, measuring (1) total processing time, (2) data extraction accuracy, (3) error detection rates, and (4) output format compliance.
- Evaluation: Use human experts to establish ground truth for accuracy assessment across all extracted data points.
Success Metrics:
- Task Automation Rate: Proportion of workflow handled end-to-end without human intervention [57]
- Processing Time: Total time from document ingestion to formatted output [57]
- Accuracy Score: Percentage of correctly extracted and validated data points [57]
- Formatting Compliance: Adherence to specified output templates and standards
Protocol 2: Scalability and Robustness Testing
Objective: Evaluate system performance under increasing loads and with problematic inputs.
Methodology:
- Load Testing: Gradually increase processing volume from 10 to 10,000 documents, monitoring system responsiveness and error rates.
- Adversarial Testing: Introduce documents with common problems including garbled PDFs, contradictory statements, and manipulated forms to test robustness [57].
- Failure Recovery: Measure system recovery time and data preservation after intentional interruption of agent processes.
- Resource Monitoring: Track computational costs, memory usage, and API call expenses throughout testing [57].
Success Metrics:
- Success Rate: Percentage of tasks completed without human escalation [57]
- Escalation Rate: Frequency of handoffs to human operators [57]
- Adversarial Robustness: Performance maintenance with problematic inputs [57]
- Resource Utilization: Computational efficiency under varying loads [57]
Workflow Visualization of a Multi-Agent System
Multi-Agent Data Extraction Workflow: This diagram illustrates the coordinated interaction between specialized agents in a research data extraction pipeline. The Retrieval Agent first processes inputs to extract relevant data, which then passes to the Validation Agent for accuracy assessment. Low-confidence items escalate to human experts, while validated data proceeds to the Formatting Agent for structuring into the final output.
The Researcher's Toolkit: Essential Components for Implementation
Table 3: Research reagent solutions for multi-agent system implementation
| Component | Function | Implementation Considerations |
|---|---|---|
| Orchestration Framework | Manages workflow between agents and handles error recovery [1] | LangGraph, custom solutions; requires durable execution capabilities [22] [1] |
| Communication Protocols | Enable information exchange between agents [56] | APIs, message queues; must ensure data consistency and avoid mismatches [56] |
| Observability Platform | Provides monitoring, debugging, and performance tracking [59] | Must support metrics, logging, and traceability for audit purposes [57] [59] |
| Evaluation Framework | Measures performance against business and technical goals [59] | Should track accuracy, cost, ROI, and user satisfaction metrics [57] |
| Access Control Layer | Manages permissions and data security across agents [56] | Critical for sensitive research data; must respect governance controls [56] |
| NMDA receptor modulator 2 | NMDA receptor modulator 2, MF:C13H11F3N2O2, MW:284.23 g/mol | Chemical Reagent |
| STAT3 degrader-1 | STAT3 degrader-1, MF:C58H63F5N9O12PS, MW:1236.2 g/mol | Chemical Reagent |
The decision between single-agent and multi-agent systems for data extraction research involves fundamental trade-offs. Single-agent systems offer simplicity, predictability, and lower computational costs, making them suitable for straightforward, sequential tasks [1]. Multi-agent systems provide parallel processing, specialized expertise, and enhanced robustness through distributed workload management [58] [1]—advantages particularly valuable for complex research tasks involving retrieval, validation, and formatting operations.
For drug development professionals and researchers, multi-agent architectures offer compelling benefits when processing diverse, unstructured data sources requiring specialized handling. The specialized agent team approach enables more accurate, efficient, and scalable data extraction pipelines, though at the cost of increased implementation complexity and computational requirements [1] [6]. As LLM capabilities continue to advance, the optimal balance may shift toward hybrid approaches that leverage the strengths of both architectures [6].
Overcoming Challenges: Optimizing AI Agent Performance and Reliability in Research
Mitigating Hallucinations and Ensuring Accuracy in Multi-Agent Systems
In the context of data extraction research, particularly for drug development, the phenomenon of AI "hallucination"—where models generate factually incorrect or fabricated information—poses a significant risk to research integrity. As large language models (LLMs) are increasingly deployed for tasks such as scientific literature review, clinical data abstraction, and chemical relationship mapping, ensuring output accuracy becomes paramount. While single-agent systems utilize one autonomous AI agent to perform tasks from start to finish, multi-agent systems coordinate several specialized agents that communicate and divide work to achieve a shared goal [23]. This guide objectively compares these approaches, focusing specifically on their capacity to mitigate hallucinations for data extraction research, supported by current experimental data and methodological protocols.
Single-Agent vs. Multi-Agent Systems: A Structural Comparison
The choice between a single-agent and multi-agent system architecture fundamentally influences a system's resilience to hallucinations. The table below summarizes their core characteristics.
Table 1: Fundamental Characteristics of Single and Multi-Agent Systems
| Aspect | Single-Agent System | Multi-Agent System |
|---|---|---|
| Definition | Involves one autonomous agent that perceives and acts to achieve its goals [23]. | Involves multiple autonomous agents that interact and cooperate to achieve shared goals [23]. |
| Interaction | Interacts only with its environment, not other agents [23]. | Agents communicate, coordinate, and cross-verify outputs [23] [60]. |
| Decision-Making | Centralized within a single agent [23]. | Distributed across multiple, specialized agents [23]. |
| Fault Tolerance | System fails if the single agent fails; errors can propagate unchecked [23] [14]. | More robust; failure or error by one agent can be contained and corrected by others [23] [14]. |
| Scalability | Limited scalability; adding functions increases complexity linearly [23]. | Highly scalable; agents can be added or removed with minimal system-wide impact [23]. |
Key Trade-offs for Data Extraction: Single-agent systems offer simplicity and lower communication overhead, making them suitable for well-defined, narrow data extraction tasks [23]. However, their monolithic nature creates a single point of failure and imposes a high cognitive load, increasing the risk of overlooked inaccuracies or logical errors [14]. Multi-agent systems address these limitations through specialization and distributed problem-solving, which naturally introduces checks and balances against hallucinations [23] [60]. The primary trade-off is the increased design, communication, and computational complexity required to coordinate multiple agents effectively [23].
Quantitative Comparison: Experimental Performance Data
Recent empirical studies directly quantify the impact of multi-agent frameworks on mitigating hallucinations. The following table consolidates key experimental findings.
Table 2: Experimental Performance Data for Hallucination Mitigation
| Study / Framework | Key Experimental Methodology | Reported Outcome on Hallucination Mitigation |
|---|---|---|
| Agentic NLP Framework (OVON) | A pipeline where 310 purpose-built prompts were processed by sequential AI agents for generation, review, and refinement [60]. | 76% reduction in Total Hallucination Scores (THS) through multi-stage refinement [60]. |
| Multi-Agent Collaborative Filtering (MCF) | Multiple agent instances generate diverse solutions; an adversarial agent selects the most accurate path using similarity scoring and cross-examination [61]. | Accuracy improvements of +5.1% on GSM8K and +3.8% on ARC-Challenge versus single-agent baselines [61]. |
| Hybrid Rule-Based & LLM Framework | An initial LLM response is verified by a reviewer agent using a custom, rule-based logic module in a controlled feedback loop [62]. | 85.5% improvement in response consistency and more predictable model outputs [62]. |
| Retrieval-Augmented Generation (RAG) | Grounding LLM outputs by retrieving information from external sources like scientific databases before generating a response [63] [64]. | Reduces hallucinations by 42-68%; medical AI applications achieved up to 89% factual accuracy with trusted sources like PubMed [63]. |
The data consistently demonstrates that multi-agent approaches yield substantial improvements in accuracy and consistency. The specialization of agents allows for dedicated fact-checking and reasoning steps that are impractical within a single, monolithic agent.
Methodological Deep Dive: Protocols for Multi-Agent Mitigation
Understanding the experimental protocols behind the data is crucial for replication and application in research settings. Below are detailed methodologies for three key multi-agent strategies.
Sequential Refinement and Review Protocol
This protocol, as implemented in the OVON-based framework, uses a linear pipeline where each agent specializes in a distinct phase of the data extraction and verification process [60].
- Step 1 – Data Extraction & Initial Generation: A front-end agent is tasked with performing the primary data extraction or answering a query from complex documents (e.g., scientific papers).
- Step 2 – Independent Review: The initial output is passed to a second-level reviewer agent, which is specifically prompted to detect unverified claims, speculative content, and logical inconsistencies. This agent often uses a different LLM to ensure diversity of analysis.
- Step 3 – Refinement & Contextualization: A third-level agent refines the text by incorporating explicit disclaimers, adding citations to source data, or rephrasing speculative statements to be clearly demarcated from factual claims.
- Step 4 – Evaluation: A dedicated fourth-level agent calculates Key Performance Indicators (KPIs) like Factual Claim Density and Explicit Contextualization Score to quantify the hallucination level [60]. The entire process is coordinated via structured JSON messages to maintain context.
Multi-Agent Collaborative Filtering (MCF) with Cross-Examination
This protocol, designed to tackle reasoning hallucinations, focuses on selecting the best output from a diverse set of candidate responses generated by multiple agents [61].
- Step 1 – Response Space Activation: For a given data extraction problem (e.g., interpreting a dose-response relationship), multiple "normal" agent instances generate independent solution paths. This creates a pool of potential answers.
- Step 2 – Adversarial Cross-Examination: A dedicated adversarial agent also generates a response. The similarity of each normal agent's response to this adversarial reference is calculated. This process incorporates Abstract Meaning Representation (AMR) to understand sentence structure and keywords beyond simple semantic similarity.
- Step 3 – Dynamic Reference from Experience Repository: Agents have access to a dynamically updated repository of successful reasoning processes from past tasks. When a new, similar data extraction task is encountered, the system retrieves and references these proven experiences. A Z-score-based outlier retrieval method prevents the use of irrelevant historical data.
- Step 4 – Optimal Path Selection: The framework selects the final response by evaluating the coherence and accuracy of each candidate, heavily weighting those that diverge from the adversarial output and align with successful historical patterns [61].
Human-in-the-Loop Intervention Protocol
This protocol integrates human expertise as a final safeguard against hallucinations in critical data extraction workflows, such as populating a clinical trial database [64].
- Step 1 – RAG-Powered Agentic Workflow: A user query is processed by an Amazon Bedrock Agent, which uses Retrieval-Augmented Generation (RAG) to ground its response in a verified knowledge base (e.g., internal research documents).
- Step 2 – Automated Hallucination Scoring: A custom Lambda function automatically evaluates the agent's response using metrics like answer correctness and answer relevancy (e.g., from the RAGAS framework).
- Step 3 – Threshold-Based Human Escalation: A pre-defined hallucination score threshold is set (e.g., 0.9 on a scale of 0 to 1). If the agent's response scores below this threshold, the system does not present the potentially hallucinated content to the user.
- Step 4 – Seamless Handoff: Instead, the workflow triggers an Amazon Simple Notification Service (SNS) notification to a pool of human experts (e.g., research scientists or data curators), who then take over the query resolution [64]. This creates a natural checkpoint for human oversight in high-stakes scenarios.
Workflow Visualization: Multi-Agent Mitigation in Action
The following diagrams illustrate the logical flow of two primary multi-agent protocols for hallucination mitigation, providing a clear visual representation of the processes described above.
Sequential Refinement Pipeline for Data Extraction
Collaborative Filtering with Experience Retrieval
The Scientist's Toolkit: Essential Reagents for Robust Multi-Agent Research
For researchers aiming to build or evaluate multi-agent systems for data extraction, the following "research reagents" and tools are essential.
Table 3: Essential Toolkit for Multi-Agent System Experimentation
| Tool / Solution | Function in the Research Context |
|---|---|
| OVON Framework | Provides universal NLP-based interfaces and structured JSON messages for transferring contextual information between specialized agents, enabling seamless interoperability [60]. |
| LangChain / LangGraph | Open-source frameworks that provide abstractions for building agentic workflows, managing memory across multi-turn conversations, and orchestrating complex, stateful task flows [65]. |
| Retrieval-Augmented Generation (RAG) | A critical grounding technique that integrates real-time knowledge retrieval from trusted sources (e.g., PubMed, internal databases) before an LLM generates a response, drastically improving factual accuracy [63] [64]. |
| Vector Databases (Pinecone, Weaviate) | Serve as the long-term memory for agents, enabling efficient storage and retrieval of relevant scientific data, past research experiences, and verified facts to cross-check agent outputs [65]. |
| Confidence Calibrators | Tools that adjust the confidence scores of an LLM's outputs, allowing researchers to set better thresholds for flagging low-confidence (and potentially hallucinated) responses for further review [65]. |
| Rule-Based Logic Modules | Custom, deterministic code that validates LLM outputs against predefined scientific rules or data schemas (e.g., checking if a reported chemical compound has a valid structure), providing a non-LLM-based verification layer [62]. |
| Amazon Bedrock Agents | A fully managed service that simplifies the building of multi-agent applications, offering built-in support for knowledge bases, dynamic workflow orchestration, and tools for evaluating model responses [64]. |
The experimental evidence is clear: for complex, high-stakes data extraction tasks in drug development and scientific research, multi-agent systems offer a demonstrably superior framework for mitigating hallucinations compared to single-agent architectures. By distributing tasks among specialized agents for generation, review, refinement, and validation, these systems introduce critical checks and balances. The resulting improvements in accuracy, consistency, and fault tolerance, as quantified by a 76% reduction in hallucination scores and 85.5% improvement in response consistency, provide researchers with a more reliable and trustworthy foundation for building AI-powered research tools. While more complex to design initially, the multi-agent paradigm is the most promising path toward achieving the level of accuracy required for mission-critical research and development.
The transition from single-agent to multi-agent architectures represents a fundamental shift in artificial intelligence system design, offering significant potential for complex task solving. However, this shift introduces the critical challenge of coordination complexity, which encompasses the difficulties in managing communication, resolving conflicts, and ensuring harmonious collaboration between autonomous agents [66]. In data extraction research—particularly in scientific and pharmaceutical domains—effective coordination is not merely an optimization concern but a prerequisite for generating reliable, reproducible results. The performance advantages of multi-agent systems are often counterbalanced by emergent coordination issues that can compromise data integrity and system efficiency [15] [4].
This guide provides an objective comparison of how single-agent and multi-agent systems manage coordination complexity, with specific emphasis on data extraction applications relevant to researchers, scientists, and drug development professionals. Through structured analysis of experimental data and architectural patterns, we illuminate the tradeoffs between these approaches and identify contexts where each excels.
Defining the Architectural Paradigms
Single-Agent Systems: Unified Control
A single-agent system operates as a centralized, unified process where one intelligence handles all aspects of a task from start to finish [1]. This architecture maintains a continuous thread of thought and action, ensuring all decisions are informed by complete contextual awareness [1]. In data extraction applications, single agents excel at tasks requiring strong state preservation and sequential logic, such as progressively building structured data from unstructured text while maintaining consistent interpretation standards throughout the process.
Multi-Agent Systems: Distributed Intelligence
Multi-agent systems employ multiple autonomous LLMs working collaboratively, typically following an orchestrator-worker pattern where a lead agent decomposes goals and delegates subtasks to specialized worker agents [1] [15]. This architecture introduces distributed context, where each agent operates with its own contextual understanding, creating both opportunities for parallel processing and challenges for contextual consistency [1]. In scientific data extraction, this enables simultaneous processing of different data modalities (text, images, tables) but requires sophisticated synchronization mechanisms to ensure cohesive interpretation.
Architectural Visualization
Quantitative Performance Comparison
Core Performance Metrics
Table 1: System Performance Metrics for Data Extraction Tasks
| Performance Metric | Single-Agent System | Multi-Agent System | Measurement Context |
|---|---|---|---|
| Token Usage | ~4× chat tokens [1] | ~15× chat tokens [1] [15] | Compared to standard chat interactions |
| Execution Speed | Sequential processing [1] | Up to 90% faster for complex queries [15] | Complex research queries with parallelizable sub-tasks |
| Coordination Overhead | None [1] | Significant; requires explicit protocols [66] | Measured via agent idle time and communication cycles |
| Error Rate | Predictable, consistent [1] | Emergent behaviors, non-deterministic [1] | Task failure rate across multiple experimental runs |
| Data Extraction Precision | Varies by task complexity | 0.96-0.98 for specialized domains [25] | Nanomaterial and nanozyme property extraction |
Task-Specific Efficiency
Table 2: Task-Based Performance Comparison
| Task Type | Single-Agent Performance | Multi-Agent Performance | Optimal Use Case |
|---|---|---|---|
| Sequential "Write" Tasks | High reliability [1] | Prone to coordination problems [1] | Code refactoring, document writing [1] |
| Parallel "Read" Tasks | Sequential bottlenecks [1] | Superior parallelization [1] | Market research, multi-source analysis [1] |
| Multimodal Data Extraction | Limited by context window [25] | High precision (0.98 F1 score) [25] | Scientific literature processing [25] |
| Financial KPI Extraction | ~65% accuracy (baseline) [67] | ~95% accuracy [67] | SEC filings, earnings reports [67] |
| Broad Information Gathering | Often fails on complex queries [15] | 90.2% performance improvement [15] | Identifying board members across S&P 500 [15] |
Experimental Protocols and Validation Methodologies
NanoMINER Multi-Agent Extraction System
The nanoMINER system exemplifies a sophisticated approach to managing coordination complexity in scientific data extraction [25]. This system employs a multi-agent architecture specifically designed for extracting nanomaterial and nanozyme properties from research literature, achieving precision scores of 0.96-0.98 for critical parameters [25].
Experimental Protocol:
- Document Processing: Input PDFs are processed to extract text, images, and plots using specialized extraction tools [25]
- Text Segmentation: Content is strategically divided into 2048-token chunks for efficient processing [25]
- Agent Coordination: A ReAct agent based on GPT-4o orchestrates specialized NER and vision agents [25]
- Modality Integration: The vision agent processes graphical data using YOLO and GPT-4o, while the NER agent extracts textual entities using fine-tuned Mistral-7B and Llama-3-8B models [25]
- Result Synthesis: The main agent aggregates information from all specialized agents to generate structured outputs [25]
Coordination Mechanism: The system employs a main agent as coordinator to manage interactions between vision and text processing agents, enabling flexible reconciliation of figure-derived data with textual descriptions [25]. This approach specifically addresses the challenge of contextual consistency across distributed agents.
Anthropic Research Agent Architecture
Anthropic's multi-agent research system demonstrates how coordination complexity is managed at scale for open-ended research tasks [15]. Their experimental protocol revealed that three factors explained 95% of performance variance: token usage (80%), number of tool calls, and model choice [15].
Coordination Protocol:
- Query Analysis: Lead agent analyzes research queries and develops investigation strategy [15]
- Parallel Subagent Spawning: Lead agent spawns 3-5 subagents to explore different aspects simultaneously [15]
- Dynamic Task Allocation: Subagents operate as intelligent filters with clearly divided responsibilities [15]
- Result Integration: Subagents return filtered information to lead agent for compilation [15]
Conflict Resolution: The system embeds explicit scaling rules in prompts to prevent coordination failures. Simple fact-finding uses 1 agent with 3-10 tool calls, direct comparisons use 2-4 subagents with 10-15 calls each, and complex research uses 10+ subagents with clearly divided responsibilities [15].
Financial KPI Extraction Framework
This experimental framework demonstrates coordination in a two-agent system for financial data extraction, achieving 95% accuracy in transforming financial filings into structured data [67].
Coordination Protocol:
- Document Preprocessing: OCR processing and logical section segmentation [67]
- Extraction Phase: Extraction agent identifies KPIs, validates using domain-tuned prompts and logic [67]
- Query Phase: Text-to-SQL agent translates natural language queries into executable SQL [67]
- Validation Loop: Structured validation across stages with iterative refinement capability [67]
Coordination Advantage: The modular design allows targeted evaluation and error handling at each stage, enabling iterative refinement that would be impossible in a single-agent architecture [67].
Coordination Workflow Visualization
Research Reagent Solutions: Essential Components for Agent Coordination
Table 3: Coordination Tools and Infrastructure Components
| Component Category | Specific Solutions | Coordination Function | Implementation Example |
|---|---|---|---|
| Communication Protocols | Model Context Protocol (MCP) [66] | Structured inter-agent communication | Anthropic's multi-agent research system [15] |
| Orchestration Frameworks | ReAct Agent [25] | Task decomposition and function calling | nanoMINER system coordination [25] |
| Specialized Processing Models | Fine-tuned Mistral-7B, Llama-3-8B [25] | Domain-specific entity recognition | NER agent in scientific extraction [25] |
| Multimodal Processing | GPT-4o, YOLO vision models [25] | Cross-modal data integration | Vision agent for figure interpretation [25] |
| Validation Infrastructure | Tool-testing agents [15] | Self-improvement and error detection | Automated prompt refinement [15] |
| Context Management | Dynamic context systems [66] | Memory and state synchronization | Financial KPI extraction validation [67] |
The comparative analysis reveals that coordination complexity in multi-agent systems presents both a significant challenge and substantial opportunity. The experimental data demonstrates that well-orchestrated multi-agent systems achieve 90.2% performance improvements on complex research tasks compared to single-agent alternatives [15], with precision scores reaching 0.98 for specialized extraction tasks [25].
For research applications requiring high-speed, parallel processing of multimodal scientific data, multi-agent architectures provide clear advantages despite their coordination overhead. However, for sequential, state-dependent tasks where contextual continuity is paramount, single-agent systems offer superior reliability and predictability [1].
The selection between these paradigms should be guided by task complexity, data modality requirements, and the value of potential performance gains relative to increased computational costs. For drug development professionals and researchers, this analysis provides a evidence-based framework for architecting AI systems that effectively balance coordination complexity against performance requirements in scientific data extraction pipelines.
Addressing the Single Point of Failure in Single-Agent Systems
A fundamental challenge in designing AI systems for critical research tasks is ensuring reliability. In single-agent architectures, the failure of the sole agent equates to total system failure, creating a significant operational risk [68]. This guide objectively compares the performance of single-agent and multi-agent systems, with a specific focus on how multi-agent designs directly address this single point of failure, supported by experimental data and protocols relevant to data extraction in scientific domains.
Single Point of Failure: A Systemic Vulnerability
In a single-agent system, one autonomous agent handles a task from start to finish—perceiving the environment, making decisions, and executing actions independently [68]. This centralized architecture is its primary weakness.
- Centralized Decision-Making: All cognitive load and operational state reside within a single agent. An error in its reasoning process, a failure in its tool use, or the agent simply exceeding its context window will halt the entire task [1].
- Limited Problem-Solving: With only one perspective and set of capabilities, the agent may struggle with complex, multi-faceted problems, leading to incomplete or failed data extraction [11].
- Consequence of Failure: As noted in comparisons, the system possesses a "single point of failure," meaning "if the agent fails, the entire system fails" [68]. This makes single-agent systems unsuitable for high-stakes or lengthy research tasks where reliability is paramount.
Systematic Comparison: Single-Agent vs. Multi-Agent Systems
The core architectural differences between these systems lead to divergent performance and reliability characteristics, summarized in the table below.
| Aspect | Single-Agent System | Multi-Agent System |
|---|---|---|
| Fault Tolerance | Low; single point of failure [68] | High; failure of one agent does not collapse the system [68] |
| Architecture | Centralized decision-making [68] | Distributed decision-making [68] |
| Scalability | Limited; complexity increases linearly [68] | Highly scalable; agents can be added/removed [68] |
| Reliability | High and predictable [1] | Lower due to emergent behaviors; but more robust [68] [1] |
| Context Management | Unified, continuous context [1] | Complex sharing required; risk of fragmentation [1] |
| Coordination Overhead | None [68] | High; critical for success [68] [1] |
| Token Usage (vs. Chat) | ~4x more tokens [1] | ~15x more tokens [1] |
| Best For | Sequential, state-dependent "write" tasks [1] | Parallelizable, exploratory "read" tasks [1] |
Experimental Evidence: Quantifying Performance Gains
Controlled experiments demonstrate the performance advantage of multi-agent systems in complex research tasks.
Experimental Protocol: Multi-Agent Research Eval
A key study from Anthropic provides a quantitative comparison of the two architectures on a data extraction task [15].
- Objective: To evaluate the ability of AI systems to comprehensively answer complex, multi-part research queries.
- Task Example: "Identify all the board members of the companies in the Information Technology S&P 500" [15].
- Models Tested: The single-agent system used Claude Opus 4. The multi-agent system used Claude Opus 4 as a lead agent, delegating parallel search tasks to Claude Sonnet 4 subagents [15].
- Methodology: Both systems were given the same set of complex queries. The multi-agent system's lead agent was designed to decompose the query, spawn subagents for parallel information gathering, and synthesize the results [15].
- Primary Metric: Success rate in finding correct and complete answers.
Results and Data Analysis
The multi-agent system outperformed the single-agent system by 90.2% on the internal research evaluation [15]. The single-agent system failed to find the correct answer, likely due to the sequential and limited nature of its searches. In contrast, the multi-agent architecture succeeded by decomposing the problem into parallelizable tasks [15].
Further analysis of performance drivers revealed that three factors explained 95% of the variance [15]:
- Token Usage (Explains 80% of variance): Multi-agent systems inherently use more tokens to solve complex problems.
- Number of Tool Calls
- Model Choice This validates the multi-agent architecture's design, which distributes work across agents with separate context windows to add more capacity for parallel reasoning [15].
Mechanisms of Fault Tolerance in Multi-Agent Systems
Multi-agent systems ensure robustness through several key mechanisms that directly counter the single point of failure.
Redundancy
Critical tasks or roles can be assigned to multiple agents [69]. In a distributed sensor network, for instance, multiple agents might monitor the same parameter. If one agent malfunctions, others continue collecting data, ensuring no loss of critical information [69]. Redundancy can be active (agents performing the same task simultaneously) or passive (backup agents remain on standby) [69].
Decentralized Decision-Making
Instead of a central controller, agents collaborate via peer-to-peer communication [69]. In a swarm robotics system, if one robot fails, nearby robots can dynamically reassign the role or adjust their paths based on shared updates. This decentralized architecture prevents single points of failure and enables real-time adaptation [69].
Error Detection and Recovery
Agents continuously monitor each other’s status through "heartbeat" signals or task completion checks [69]. If an agent fails to respond, others trigger recovery actions, such as restarting the agent or redistributing its tasks. Strategies like checkpointing—where system states are saved periodically—allow the system to roll back to a stable state and resume after a failure [69].
These mechanisms create a system that is inherently more resilient and capable of handling the unpredictable nature of real-world research environments.
The Scientist's Toolkit: Research Reagent Solutions
Building a reliable multi-agent system for data extraction requires a suite of core components, each with a distinct function.
| Component | Function & Rationale |
|---|---|
| Orchestrator (Lead Agent) | The central brain; analyzes the query, develops a strategy, delegates tasks to subagents, and synthesizes final results. Critical for coordination [15]. |
| Specialized Sub-agents | Domain-specific workers (e.g., NER Agent, Vision Agent) tasked with parallel execution of subtasks. Enable division of labor and parallelization [25]. |
| Tool Set (MCP Servers) | External tools and data sources (e.g., search APIs, databases, PDF parsers, YOLO for visual data). Agents use these to interact with the environment and gather information [15] [25]. |
| Communication Layer | The protocol for message passing and state sharing between agents (e.g., a "research pad" or shared memory). Mitigates context fragmentation [33]. |
| Monitoring & Recovery | Mechanisms for fault detection (e.g., heartbeats) and recovery (e.g., task redistribution, checkpointing). Ensures system resilience [69]. |
For researchers, scientists, and drug development professionals, the choice between single and multi-agent systems has significant implications for data integrity and project reliability. While single-agent systems offer simplicity, they introduce a critical single point of failure. Multi-agent systems, through architectural principles like redundancy, decentralized control, and active recovery mechanisms, directly address this vulnerability. Experimental evidence confirms that they achieve superior performance on complex data extraction tasks, making them a more robust and scalable choice for accelerating scientific discovery.
Optimizing for Scalability and Computational Resource Management
The transition from single-agent to multi-agent architectures represents a significant evolution in artificial intelligence systems for data extraction research. While single-agent systems utilize one large language model (LLM) to handle all aspects of a task, multi-agent systems employ multiple specialized LLMs working in coordination [19] [70]. This architectural decision profoundly impacts scalability and computational efficiency, determining whether systems can handle growing data volumes and complexity without exponential resource increases. Understanding this trade-off is particularly crucial for research and drug development professionals working with extensive scientific literature and complex experimental data.
This guide objectively compares the performance characteristics of both approaches, supported by experimental data from recent implementations across various domains, including financial analysis, systematic literature reviews, and medical data extraction.
Performance and Scalability Comparison
The table below summarizes key quantitative findings from recent studies comparing single-agent and multi-agent system performance across different domains and tasks.
| Domain & Task | Single-Agent Performance | Multi-Agent Performance | Computational Cost Difference | Key Findings |
|---|---|---|---|---|
| Financial KPI Extraction [67] | ~85% accuracy (estimated baseline) | ~95% accuracy | Not specified | Matches human annotator performance; generalizes across document types |
| Systematic Literature Reviews [71] | F1 scores: 0.22-0.85 (varies by complexity) | Not directly compared | Not specified | Performance decreases with data complexity; simple data: F1>0.85, complex data: F1=0.22-0.50 |
| Web Research Tasks [15] | Baseline performance | 90.2% improvement over single-agent | Multi-agent uses ~15× more tokens than chats | Performance variance explained by tokens (80%), tool calls, and model choice |
| Breast Cancer Pathology [72] | Not applicable | 97.4% overall accuracy (PubMedBERT) | Not specified | 30 of 32 fields with >95% accuracy; outperformed previous rule-based algorithm (95.6%) |
Scalability Analysis: Multi-agent systems demonstrate superior performance in complex extraction tasks but incur significantly higher computational costs [15]. The Anthropic research team found that multi-agent systems used approximately 15 times more tokens than simple chat interactions, with agents typically using about 4 times more tokens than chats [15]. This creates a fundamental trade-off where performance gains must be balanced against computational expense.
Experimental Protocols and Methodologies
Financial KPI Extraction Protocol
A 2025 study developed a specialized two-agent system for extracting key performance indicators from financial documents [67]. The Extraction Agent identified KPIs from unstructured financial text, standardized formats, and verified accuracy, while the Text-to-SQL Agent generated executable SQL statements from natural language queries [67]. The system was evaluated on diverse SEC filings (10-Ks, 10-Qs, 8-Ks) with human evaluators rating response correctness for retrieval tasks [67].
Medical Systematic Review Protocol
Researchers developed prompt engineering strategies for GPT-4o to extract data from randomized clinical trials across three disease areas [71]. During development, prompts were iteratively refined through repeated testing and modification until performance thresholds were met (F1 score >0.70) [71]. Performance was evaluated using F1 scores, precision, recall, and percentage accuracy compared to human extraction [71].
Breast Cancer Pathology Extraction Methodology
This study implemented a domain-specific extractive question-answering pipeline to automate extraction of 32 fields from synoptic breast cancer pathology reports [72]. The methodology involved data preprocessing, model development (pre-training & fine-tuning), and post-processing model predictions [72]. Researchers compared four candidate models (ClinicalBERT, PubMedBERT, BioMedRoBERTa, and Mistral-Nemo LLM) on 1,795 reports [72].
Architecture comparison showing sequential vs. orchestrated workflows
The Researcher's Toolkit
| Component | Function | Example Implementations |
|---|---|---|
| Orchestrator Agent | Coordinates workflow, delegates tasks to specialized agents | Determines which agents to call and in what order [70] |
| Extraction Agent | Identifies and validates target data from source documents | Uses domain-tuned prompts and logic for financial KPI extraction [67] |
| Evaluation Frameworks | Measures system performance across multiple dimensions | Galileo Agent Leaderboard, Ï„-bench, PlanBench [73] |
| Specialized LLMs | Domain-optimized models for specific tasks | PubMedBERT (medical data), FinancialBERT (financial data) [72] |
| Prompt Engineering | Optimizes LLM instructions for improved accuracy | Iterative refinement against validation sets [71] [74] |
Computational resource distribution in different architectural approaches
Key Optimization Strategies
Strategic Agent Specialization
Multi-agent systems enable optimized resource allocation through specialized agents. As demonstrated in financial extraction systems, dedicated Extraction Agents and Text-to-SQL Agents can be independently tuned for their specific tasks [67]. This specialization allows for using appropriately sized models for each task rather than a single oversized model handling all operations [70].
Cost-Performance Balancing
The token efficiency trade-off requires careful consideration. Anthropic's research found multi-agent systems used approximately 15× more tokens than chat interactions but delivered 90.2% performance improvement on research tasks [15]. This suggests multi-agent approaches are economically viable primarily for high-value tasks where performance justifies computational expense.
Hybrid Architecture Design
Successful implementations often employ hierarchical multi-agent systems where an orchestrator agent (using a advanced model) coordinates specialized workers (using mid-tier models) [15] [14]. This approach balances coordination capabilities with computational efficiency, optimizing overall system performance while managing resource utilization.
The choice between single-agent and multi-agent systems for data extraction research involves fundamental trade-offs between performance, scalability, and computational resource consumption. Single-agent systems offer computational efficiency and simpler architecture but face limitations in handling complex, multi-faceted extraction tasks. Multi-agent systems provide superior performance for complex extractions and better scalability through specialized分工 but incur significantly higher computational costs.
For research and drug development professionals, the optimal approach depends on specific use case requirements. When working with well-structured data and standardized extraction requirements, single-agent systems may provide sufficient performance with better resource utilization. For complex, multi-dimensional extraction tasks involving diverse data sources and requirements, the performance advantages of multi-agent systems typically justify their higher computational costs, particularly when implemented with careful attention to resource optimization strategies.
Implementing Effective Human-in-the-Loop Oversight for Critical Data Points
In the high-stakes field of drug development, the accuracy of extracted data points directly impacts research outcomes, regulatory compliance, and patient safety. As artificial intelligence transforms preclinical research, establishing effective human-in-the-loop (HITL) oversight has become essential for validating critical information. This comparison guide examines how HITL implementation differs between single-agent and multi-agent AI systems, providing researchers with evidence-based insights for architectural decisions.
The pharmaceutical industry faces mounting pressure to accelerate drug development while maintaining rigorous data quality standards. AI-driven data extraction platforms must balance automation with expert oversight, particularly when handling complex, unstructured data from diverse sources such as study reports, laboratory findings, and clinical documents [75]. This analysis compares HITL efficacy across architectural paradigms, focusing on quantitative performance metrics, error reduction capabilities, and implementation complexity for scientific workflows.
System Architectures and HITL Integration Patterns
Single-Agent Architecture with HITL
Single-agent AI systems employ one intelligent agent that handles the entire task lifecycle—from ingesting inputs and reasoning to tool use and output generation [11]. These systems connect to APIs or databases via protocols like the Model Context Protocol or RESTful services while managing their own memory and state.
In single-agent systems, HITL typically functions as a sequential checkpoint. The architecture follows a linear workflow: input → reasoning → action → human validation → output. This approach centralizes decision-making within a single model context, making HITL implementation relatively straightforward through confirmation prompts or review interfaces [76]. For example, a single-agent system might process a document through retrieval-augmented generation (RAG) and present its extractions to a human reviewer for verification before database storage.
Single-Agent HITL Workflow: Human validation occurs at a single checkpoint after tool execution.
Multi-Agent Architecture with HITL
Multi-agent systems employ specialized agents working collaboratively under an orchestrator [75]. The PRINCE platform exemplifies this architecture with a Supervisor Agent that analyzes user intent, a Reflection Agent that evaluates data sufficiency, and specialized agents for document planning and information retrieval [75].
HITL in multi-agent systems operates at multiple potential intervention points, creating a more nuanced oversight model. The Supervisor Agent can request human input for ambiguous queries, the Document Planner Agent can incorporate human feedback on document structure, and the Reflection Agent can flag uncertain extractions for expert review. This distributed oversight allows human experts to intervene precisely where their expertise is most valuable.
Multi-Agent HITL Workflow: Human oversight is distributed across specialized agents and validation points.
Performance Comparison: Quantitative Metrics
Data Extraction Accuracy and Error Reduction
Table 1: Performance Metrics for Single-Agent vs. Multi-Agent Systems with HITL
| Performance Metric | Single-Agent with HITL | Multi-Agent with HITL | Measurement Context |
|---|---|---|---|
| Faithfulness Score | 84% | 92% | Evaluation of factual correctness against source documents [75] |
| Answer Relevancy | 81% | 95% | Relevance of extracted data to original query [75] |
| Error Reduction with HITL | 47% | 68% | Reduction in hallucination and factual errors [75] |
| Context Precision | 79% | 91% | Precision in retrieving relevant context chunks [75] |
| Handling Complex Queries | 73% accuracy | 94% accuracy | Multi-domain query resolution [76] |
| Architecture Optimization | 11% improvement | 90.2% improvement | Internal evaluations of specialized vs. generalist approaches [11] |
Multi-agent systems demonstrate superior performance across all measured accuracy metrics, particularly for complex, multi-domain data extraction tasks. The PRINCE platform achieved 92% faithfulness and 95% answer relevancy scores in pharmaceutical data extraction, significantly outperforming single-agent approaches [75]. The architectural advantage emerges from specialized agents focusing on discrete subtasks with targeted human validation, reducing error propagation through the workflow.
Operational Efficiency and Implementation Metrics
Table 2: Operational Efficiency and Implementation Comparison
| Operational Metric | Single-Agent with HITL | Multi-Agent with HITL | Implementation Context |
|---|---|---|---|
| Development Speed | Hours to days [11] | Weeks to months | Initial implementation timeline |
| HITL Integration Complexity | Low | Medium-High | Implementation effort for oversight mechanisms [77] |
| Computational Resources | Lower requirements | Requires orchestration platforms, task queues [11] | Infrastructure demands |
| Human Review Rate | 15-25% of outputs | 8-12% of outputs (targeted review) | Percentage of outputs requiring human intervention |
| Query Response Time | Faster for simple queries (<30s) | Slower initial response (60-90s) [76] | Average response latency |
| Scalability | Limited for complex workflows | Superior for multi-domain tasks [11] | Ability to handle increasing task complexity |
While single-agent systems offer implementation advantages for straightforward data extraction tasks, multi-agent architectures provide better scalability for complex research environments. The development trade-off is evident: single-agent systems can be deployed rapidly with simpler HITL integration, while multi-agent systems require more substantial initial investment but deliver greater efficiency at scale through targeted human oversight [11].
Experimental Protocols and Validation Methodologies
Evaluation Framework for HITL Effectiveness
Research institutions have developed standardized protocols to quantitatively assess HITL implementation effectiveness across AI architectures:
Dataset Curation Protocol:
- Develop comprehensive question-answer pairs covering complexity levels from simple fact extraction to multi-document synthesis
- Engage domain experts to create reference answers with source documentation
- Categorize questions by cognitive demand: factual, analytical, synthetic
- Maintain evaluation datasets in specialized platforms (e.g., Langfuse) for continuous assessment [75]
Performance Measurement Protocol:
- Execute curated questions through the AI system with HITL mechanisms active
- Calculate quantitative metrics: faithfulness, answer relevancy, context precision
- Employ custom evaluation scripts to compare generated responses against reference answers
- Conduct evaluations at intermediate process stages to identify error points [75]
HITL Impact Assessment Protocol:
- Measure error reduction before and after human intervention
- Calculate time-to-resolution for corrected outputs
- Assess human effort required for validation across architectures
- Track error patterns to optimize HITL placement
PRINCE Platform Validation Methodology
The PRINCE multi-agent system implemented at Bayer AG exemplifies rigorous HITL validation:
- Deployed multi-agent architecture with LangGraph management
- Integrated specialized agents for retrieval, reflection, and document planning
- Incorporated HITL nodes for user feedback during document drafting
- Implemented hybrid search (vector similarity + keyword matching) with weighted scoring
- Employed cross-encoder reranking models (bge-reranker-large) for relevance assessment [75]
This methodology demonstrated that targeted HITL integration in multi-agent systems could achieve 92% faithfulness in pharmaceutical data extraction while only requiring human intervention for 8-12% of outputs [75].
Implementation Guide: HITL Patterns for Scientific Data Extraction
Human Validation Frameworks
User Confirmation Pattern: This approach provides straightforward Boolean validation, pausing execution for user approval before conducting critical actions [77]. Implementation involves:
- Identifying critical data extraction points requiring confirmation
- Configuring agent to request user confirmation before executing sensitive operations
- Presenting extracted parameters for review before database modification
- Ideal for discrete operations with clear success criteria
Return of Control (ROC) Pattern: ROC enables deeper human intervention by returning control to the application for parameter modification [77]. Implementation includes:
- Configuring ROC at action group level for multiple related operations
- Developing interfaces for parameter editing before execution
- Implementing application-level validation in addition to agent validation
- Suitable for complex extractions requiring nuanced human judgment
Tiered Oversight Strategy
Implementing adaptive HITL oversight based on data criticality and complexity optimizes human resource utilization:
Autonomous Processing:
- Routine, well-structured data extraction
- High-confidence model predictions with supporting evidence
- Non-critical research data with low error impact
Confirmation-Required Processing:
- Medium-criticality extractions affecting experimental interpretations
- Medium-confidence predictions with partial evidence
- Regulatory documentation requiring verification
Return of Control Processing:
- High-criticality extractions influencing safety conclusions
- Complex multi-document synthesis tasks
- Regulatory submission documents requiring expert refinement [78]
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Research Reagents for HITL AI Implementation
| Reagent Solution | Function | Implementation Example |
|---|---|---|
| LangGraph | Multi-agent system management and orchestration | Coordinates specialist agents in PRINCE platform [75] |
| Vector Databases | Semantic storage and retrieval of document chunks | Amazon OpenSearch with hybrid search capabilities [75] |
| Cross-Encoder Rerankers | Relevance assessment for retrieved information | bge-reranker-large model for precision optimization [75] |
| Evaluation Platforms | Performance tracking and metric calculation | Langfuse for dataset management and metric tracking [75] |
| Text Embedding Models | Semantic vector representation for retrieval | text-embedding-3-large for chunk embedding [75] |
| Confidence Threshold Config | Automated HITL triggering based on uncertainty | Flag outputs below 80% confidence for human review [79] |
| Audit Trail Systems | Compliance documentation for regulatory requirements | Track all AI decisions with human validation timestamps [80] |
The comparison reveals a clear architectural preference based on research complexity and data criticality. Single-agent systems with HITL provide satisfactory performance for narrow, well-defined data extraction tasks where development speed and simplicity are prioritized. Their unified context and straightforward HITL integration make them ideal for focused applications with limited scope.
Multi-agent systems with distributed HITL significantly outperform for complex, multi-domain research tasks common in drug development. The PRINCE platform demonstrates that specialized agents with targeted human validation achieve 92% faithfulness in pharmaceutical data extraction [75]. Despite higher implementation complexity, the architectural advantage emerges from task specialization, collaborative reasoning, and precision oversight placement.
For research institutions implementing HITL for critical data points, the evidence supports multi-agent architectures when handling diverse data sources, complex extraction requirements, and regulatory compliance needs. The initial development investment yields substantial returns in accuracy, scalability, and ultimately, research reliability.
Validating Performance: A Rigorous Comparison of Accuracy and Efficiency
In evidence-based research, particularly in fields like medicine and drug development, the process of data extraction from existing literature is a critical yet time-consuming and error-prone task [48]. The established "gold standard" for ensuring accuracy in this process is human double extraction, a method where two human reviewers independently extract data from the same studies, followed by a cross-verification process to resolve discrepancies [48]. While highly accurate, this method is exceptionally labor-intensive, creating a significant bottleneck in systematic reviews and meta-analyses [48].
Artificial Intelligence (AI), particularly in the form of Large Language Models (LLMs), has emerged as a promising tool to accelerate this process. This guide objectively compares the performance of two dominant AI architectures—single-agent and multi-agent systems—for data extraction, benchmarking them against the human double extraction gold standard. The central thesis is that while single-agent AI offers simplicity, emerging evidence suggests multi-agent systems, through specialized collaboration, may more reliably approximate human-level accuracy for complex extraction tasks.
Experimental Protocols: Methodologies for Benchmarking
To evaluate AI performance against human double extraction, researchers employ structured experimental designs. The following workflows and methodologies are central to generating comparable performance data.
Workflow Architecture for Data Extraction
The diagram below illustrates the core workflows for the three primary data extraction methods: human double extraction, single-agent AI, and multi-agent AI.
Key Experimental Designs
Randomized Controlled Trial (RCT) for AI-Human Hybrid vs. Human Double Extraction A pivotal study design is a randomized, controlled, parallel trial where participants are assigned to either an AI group or a non-AI group [48].
- AI Group: Uses a hybrid approach where an AI tool (e.g., Claude 3.5) performs the initial data extraction, followed by human verification of the AI output by the same participant [48].
- Non-AI Group: Uses traditional human double extraction, where two participants extract data independently, followed by cross-verification [48].
- Primary Outcome: The percentage of correct extractions for specific tasks, such as extracting group sizes and event counts from randomized controlled trials in systematic reviews [48].
- Gold Standard Reference: A pre-existing, error-corrected database of meta-analyses serves as the benchmark for evaluating extraction accuracy [48].
Comprehensive Benchmarking of Agent Architectures (AgentArch) The AgentArch benchmark provides a framework for evaluating 18 distinct agentic configurations across enterprise tasks, examining four key dimensions [81]:
- Orchestration Strategy: Single-agent versus multi-agent (e.g., open vs. isolated orchestration).
- Agent Style: Function calling versus ReAct (Reasoning and Acting) prompting.
- Memory Management: Complete history versus summarized history.
- Thinking Tool Integration: Enabled versus disabled chain-of-thought reasoning. This benchmark tests these architectures on tasks of varying complexity, from simple structured workflows to complex intelligent routing, providing a multi-faceted view of performance [81].
Performance Data: Single-Agent vs. Multi-Agent vs. Human
The table below synthesizes quantitative performance data from recent experimental results and benchmarks, comparing the two AI architectures and the human gold standard.
Table 1: Performance Comparison of Data Extraction Methods
| Metric | Single-Agent AI | Multi-Agent AI | Human Double Extraction (Gold Standard) |
|---|---|---|---|
| Reported Accuracy | Variable; can surpass single human extraction but falls short of double extraction [48]. Performance degrades significantly with increasing tool count and context size [82]. | Outperformed single-agent Claude Opus 4 by 90.2% on an internal research evaluation [15]. Can approach the reliability of human double extraction for specific, parallelizable tasks [48] [15]. | Highest accuracy; serves as the benchmark. Error rates at the study level are ~17% without double extraction [48]. |
| Typical Success Rate (Enterprise Tasks) | Up to 67.7% on simpler tasks with optimal configuration (function calling, complete memory) [81]. | Success rates are highly architecture-dependent; can match or exceed single-agent on complex tasks requiring coordination [81]. | Not quantified as a "success rate" in benchmarks, as it is the reference for 100% correctness. |
| Efficiency & Scalability | Faster decision-making for simple, linear tasks [11]. Performance drops with complex, multi-faceted problems [11]. | Excels at complex, multi-step tasks through parallelization and specialization [2] [15]. | Highly time-consuming and labor-intensive, creating a significant bottleneck in evidence synthesis [48]. |
| Resource Cost (Tokens) | Lower cost than multi-agent systems. | High cost; multi-agent systems can use ~15x more tokens than chat interactions and ~4x more than single-agent systems [15]. | No computational cost, but high personnel time cost. |
| Failure Mode | Single point of failure; the entire system fails if the agent encounters an error [11]. Struggles with tasks exceeding its context window or requiring diverse expertise [2]. | More resilient; if one agent fails, others can potentially compensate [11]. Challenges include communication overhead and coordination complexity [19]. | Susceptible to human error if performed by a single individual; double extraction mitigates this. |
Performance in Different Architectural Configurations
The choice of architecture and components significantly impacts the performance of AI extraction systems, as revealed by the AgentArch benchmark [81]. The data highlights that there is no one-size-fits-all solution.
Table 2: AgentArch Benchmark Snapshot: Success Rates by Architecture (%) [81]
| Orchestration | Agent Style | Memory | Model: GPT-4.1 (Simple Task) | Model: Sonnet 4 (Simple Task) |
|---|---|---|---|---|
| Single-Agent | Function Calling | Complete | 58.8 | 67.7 |
| Single-Agent | ReAct | Complete | 36.9 | 28.1 |
| Multi-Agent | Function Calling | Complete | 58.8 | 68.5 |
| Multi-Agent | ReAct | Complete | 28.7 | 28.3 |
Key Insights from AgentArch Data:
- Agent Style is Critical: Function calling consistently and significantly outperforms ReAct prompting in both single and multi-agent setups across most models [81].
- No Universal Winner: For simpler tasks, a well-configured single-agent (function calling, complete memory) can achieve performance on par with a multi-agent system [81].
- Model Dependency: The optimal architecture is highly dependent on the underlying LLM. For instance, GPT-4.1 performed poorly with ReAct in multi-agent settings, while Sonnet 4 showed more robust performance across architectures [81].
The Scientist's Toolkit: Research Reagent Solutions
This section details the essential "reagents" or components required to build and evaluate AI data extraction systems in a research context.
Table 3: Essential Components for AI Data Extraction Systems
| Component | Function & Description | Examples |
|---|---|---|
| LLM Core | The central reasoning engine responsible for understanding, planning, and generating text. Its capabilities determine the system's base performance. | Claude 3.5/Opus, GPT-4 series, LLaMA 3.3 70B [48] [81] [15]. |
| Orchestration Framework | Software that manages the workflow, agent communication, and state management. It is the backbone of multi-agent systems. | LangGraph (Supervisor, Swarm), CrewAI, AutoGPT [82] [11]. |
| Tool & API Access | Enables agents to interact with external systems, such as search the web, query databases, or use computational tools. | MCP (Model Context Protocol) servers, custom APIs, web search tools [15]. |
| Memory Module | Manages the agent's short-term and long-term state, allowing it to retain context and learn from past actions in a session. | Vector databases (VectorDB), Redis, dual-track memory systems [81] [2]. |
| Evaluation Benchmark | A standardized dataset and set of metrics to quantitatively assess the accuracy and efficiency of the extraction system. | Ï„-bench (modified), AgentArch, MultiAgentBench, domain-specific gold-standard databases [48] [82] [81]. |
| Prompting Strategy | A pre-defined and refined set of instructions that guides the agent's behavior, role, and output format. | Role-based prompts, iterative prompt refinement, chain-of-thought (CoT), ReAct [48] [81] [15]. |
Logical Pathway for Method Selection
The decision to use a single-agent, multi-agent, or human-centric data extraction method depends on the task's complexity, required accuracy, and available resources. The following diagram outlines the logical decision pathway.
The establishment of human double extraction as the gold standard provides a critical benchmark for evaluating emerging AI methodologies. The experimental data and benchmarks presented demonstrate that both single-agent and multi-agent AI systems are viable contenders, but with distinct performance profiles.
- Single-Agent AI offers a compelling balance of performance and simplicity for well-defined, narrower data extraction tasks, especially when configured with function calling and complete memory.
- Multi-Agent AI shows transformative potential for complex, multi-faceted research tasks, demonstrating the ability to outperform single agents significantly by leveraging specialization and parallelization. Its current limitations include high computational costs and coordination complexity.
The future of automated data extraction does not lie in a single approach replacing humans, but in AI-human hybrid models [48]. For the foreseeable future, the most reliable and efficient path for critical research synthesis, such as in drug development, will involve AI systems performing the heavy lifting of initial data processing, with human experts providing the essential verification, oversight, and complex judgment that remains the ultimate gold standard.
The architectural choice between single-agent and multi-agent systems is a pivotal decision in designing artificial intelligence (AI) solutions for complex research tasks, including those in data extraction and drug development. A single-agent system relies on one AI entity to perceive its environment, make decisions, and execute actions, making it suitable for straightforward, well-defined problems [83] [84]. In contrast, a multi-agent system (MAS) employs multiple autonomous agents that can interact, cooperate, or work independently, often leading to enhanced performance in dynamic and complex environments [83] [19]. For researchers and scientists, understanding the nuanced trade-offs between these architectures across key performance metrics is fundamental to building efficient, reliable, and scalable intelligent systems. This guide provides an objective, data-driven comparison to inform these critical design choices, with a specific focus on applications in data-centric research.
Core Architectural Comparison
The fundamental differences between single-agent and multi-agent systems can be visualized as a spectrum of organizational control. The following diagram illustrates the core architectural workflow of each system, highlighting the centralized nature of single-agent designs versus the distributed, collaborative nature of multi-agent designs.
Quantitative Metric Comparison
The architectural differences lead to distinct performance profiles. The following table summarizes the comparative performance of single-agent and multi-agent systems across the critical metrics of accuracy, scalability, and fault tolerance, synthesizing findings from recent research and real-world applications.
Table 1: Comparative Performance Across Key Metrics
| Metric | Single-Agent System | Multi-Agent System | Supporting Evidence & Context |
|---|---|---|---|
| Accuracy | Performance is constrained on problems requiring diverse expertise or integrated reasoning [19]. Struggles with complex, multi-faceted tasks. | Superior on complex, decomposable tasks. Excels in breadth-first queries and parallelizable problems [15]. | A multi-agent system for financial data extraction achieved ~95% accuracy in transforming unstructured filings into structured data, matching human annotator performance [67]. In internal research evaluations, a multi-agent system outperformed a single-agent setup by 90.2% on complex research tasks [15]. |
| Scalability | Limited. Performance degrades as complexity grows. Adding more context or tools increases compute cost, latency, and can lead to "lost in the middle" effects where key information is ignored [84]. | High. Inherently modular and parallelizable. Workload can be distributed across specialized agents, allowing the system to handle broader and more dynamic environments [83] [84]. | Scaling a single-agent system often means using larger context windows, which spreads attention and increases costs [84]. Multi-agent systems scale by adding agents, enabling parallel processing. For instance, parallel tool calling in a research system cut query resolution time by up to 90% [15]. |
| Fault Tolerance | Low. A failure in the single agent jeopardizes the entire operation. The system is a single point of failure [83] [84]. | High. Inherently resilient. If one agent fails, others can adapt or compensate, maintaining operational continuity. This self-healing capability is valuable in mission-critical environments [83]. | This is a foundational design advantage. The system is designed so that the failure of an individual component does not lead to total system collapse, providing built-in redundancy [84]. |
Detailed Experimental Protocols
To ground the comparative metrics in practical research, this section details the methodology from a landmark study that demonstrated the high accuracy of a multi-agent system in a data extraction domain, a task highly relevant to scientific research.
Protocol: Multi-Agent System for Financial KPI Extraction
This experiment validated a two-agent system for extracting and querying key performance indicators (KPIs) from unstructured financial documents, a process analogous to extracting structured data from scientific literature or reports [67].
Table 2: Research Reagent Solutions for Data Extraction
| Research Reagent | Function in the Experimental Protocol |
|---|---|
| Unstructured Financial Documents | The raw input data (e.g., 10-K, 10-Q filings) from which structured information is to be extracted. Serves as the test corpus. |
| Extraction Agent | A specialized LLM-based agent responsible for identifying KPIs from text, standardizing their formats, and verifying accuracy using domain-tuned prompts and logic. |
| Text-to-SQL Agent | A specialized LLM-based agent that generates executable SQL statements from natural language queries, enabling precise retrieval of the structured data. |
| Domain-Specific Embedding Models | Used to identify KPI-relevant segments within the documents during preprocessing, improving retrieval precision. |
| Human Evaluators | Acted as the gold standard for accuracy, rating system responses in the retrieval task to calculate the final correctness score. |
Workflow Diagram: The experimental workflow for the financial KPI extraction system demonstrates a clear, sequential pipeline where two specialized agents perform distinct, critical functions.
Methodology Details:
- Input: The process began with raw, unstructured financial documents (PDFs, HTML).
- Preprocessing: Documents underwent OCR (if needed), logical section segmentation, text normalization, and numeric span detection.
- Structuring (Extraction Agent): The Extraction Agent parsed the preprocessed text, identifying KPIs, fiscal periods, and metadata. Its core function was to validate these extractions using integrated domain-specific logic, ensuring reliability across diverse financial disclosures.
- Storage: The validated, structured data was placed into a structured database.
- Querying (Text-to-SQL Agent): The Text-to-SQL Agent translated natural language queries from analysts into executable SQL statements, enabling precise retrieval of information from the structured database.
- Evaluation: The system's performance was evaluated on two fronts:
- Extraction Accuracy: The transformation of raw filings into structured data was assessed, achieving approximately 95% accuracy.
- Retrieval Correctness: In a human evaluation of the retrieval task, 91% of the system's responses were rated as correct by human evaluators [67].
The Researcher's Toolkit: Agent System Components
Building and evaluating robust agent systems requires a suite of specialized tools and frameworks. The following table catalogs essential "research reagents" for developers and scientists working in this field.
Table 3: Essential Tools for Agent Development and Monitoring
| Tool Category | Representative Technologies | Function & Application |
|---|---|---|
| Agent Frameworks | LangChain, LangGraph, AutoGen, CrewAI [22] [85] | Facilitate the implementation of agentic patterns, memory management, multi-turn conversations, and tool integration. Essential for prototyping and building both single and multi-agent systems. |
| Vector Databases | Pinecone, Weaviate, Chroma [85] | Store and efficiently retrieve vector embeddings of data. Critical for powering agent memory and retrieval-augmented generation (RAG) pipelines that provide agents with relevant contextual information. |
| Monitoring & Evaluation | Maxim AI, Langfuse, Arize Phoenix [86] | Provide observability into an agent's reasoning steps, tool calls, and retrievals. They enable tracking of performance metrics, detection of hallucinations or drift, and continuous evaluation of agent behavior in production. |
| Model Orchestration | Custom LLM Orchestrators, Deterministic Workflow Engines [84] | Dynamically coordinate, instruct, and mediate between multiple agents. An LLM orchestrator can interpret goals and assign tasks adaptively, while deterministic engines offer predictable, rule-based control. |
The comparative data leads to a clear, though nuanced, conclusion: there is no universally superior architecture. The optimal choice is dictated by the specific problem profile.
Single-agent systems offer a compelling combination of simplicity, predictability, and lower operational overhead, making them the appropriate choice for problems with a well-defined scope, a single context, and limited requirements for parallel processing [84]. Their primary weaknesses emerge in highly complex, dynamic, or large-scale environments where their limited scalability and low fault tolerance become significant liabilities.
Multi-agent systems, by contrast, excel in precisely these challenging environments. Their strengths in specialization, parallel processing, and inherent resilience make them uniquely capable for decomposable problems, dynamic environments, and mission-critical applications where a single point of failure is unacceptable [83] [84]. This comes at the cost of significantly higher system complexity, resource consumption, and challenging debugging processes [84]. Furthermore, the performance gains are not free; one analysis noted that multi-agent systems can use about 15 times more tokens than simple chat interactions, a critical economic factor for researchers to consider [15].
For the research and drug development community, this analysis suggests a pragmatic path forward. Single-agent systems are sufficient and efficient for focused, well-bounded data extraction or analysis tasks. However, for large-scale, complex research initiatives—such as cross-referencing multiple scientific databases, validating findings against a vast corpus of literature, and generating integrated reports—a multi-agent architecture is likely necessary to achieve the required levels of accuracy, scale, and robustness. Future advancements may lie in hybrid paradigms that dynamically route tasks between single and multi-agent subsystems, optimizing for both efficiency and capability [6].
The research landscape for data extraction is increasingly defined by a choice between two distinct paradigms: single-agent systems (AI- or human-only) and multi-agent systems (human-AI collaboration). In single-agent systems, a task is completed entirely by an artificial intelligence or a human working independently. In contrast, multi-agent, or hybrid, systems are "human–AI systems involving different tasks, systems and populations" designed to leverage the complementary strengths of both [87]. The central question for researchers and drug development professionals is not merely which paradigm is superior, but rather under what specific conditions does each yield optimal performance, accuracy, and efficiency. This review synthesizes current evidence from randomized trials and empirical studies to provide a data-driven comparison, offering clarity for strategic implementation in scientific and clinical settings.
Recent large-scale meta-analyses provide a high-level perspective on the performance of these competing paradigms. The overarching finding is that the average performance of human-AI collaborations is more nuanced than commonly assumed.
Table 1: Overall Performance from Meta-Analyses
| Performance Metric | Single-Agent (AI Only) | Single-Agent (Human Only) | Multi-Agent (Human-AI Collaboration) |
|---|---|---|---|
| Performance vs. Best Single Agent | Baseline (Best) | Baseline (Best) | On average, performs worse than the best of humans or AI alone (Hedges’ g = -0.23) [87] |
| Performance vs. Humans Alone | N/A | Baseline | On average, performs better than humans alone (Hedges’ g = 0.64) [87] |
| Task-Based Variability | Excels in data-driven, repetitive tasks [88] | Excels in contextual understanding and emotional intelligence [88] | Performance losses in decision tasks; gains in creation tasks [87] |
| Impact of Relative Performance | Most effective when AI outperforms humans [87] | Most effective when humans outperform AI [87] | Gains when humans are stronger; losses when AI is stronger [87] |
A pivotal finding from a systematic review in Nature Human Behaviour is that, on average, human-AI combinations performed significantly worse than the best of humans or AI alone [87]. This indicates that simply layering AI onto a human-driven process, or vice versa, does not guarantee superior outcomes and can be detrimental. However, the same analysis found substantial evidence of human augmentation, meaning these combinations do generally outperform human-only systems [87]. The critical implication is that multi-agent systems are a reliable tool for elevating human performance but may not achieve the absolute peak performance possible from the single best agent for a given task.
Evidence in Data Extraction and Research Contexts
Applying this framework to data extraction—a critical task in drug development and scientific research—reveals specific performance characteristics. The paradigm choice here directly influences data quality, volume, and processing speed.
Table 2: Data Extraction Methods and Performance (2025 Benchmark)
| Extraction Method | Typical Data Type | Key Performance Metrics | Ideal Use Case |
|---|---|---|---|
| API Extraction | Structured | Real-time speed; high scalability; simplifies integration [89] | Direct access to structured databases for real-time dashboards |
| AI-Powered Web Scraping | Semi-structured (Dynamic) | 30% increase in extraction accuracy; adaptive to website changes [89] | Collecting market intelligence and competitive data from dynamic web sources |
| ETL Systems | All Types (Batch) | 40% reduction in processing time (Apache NiFi case); high scalability [89] | Managing and transforming diverse, large-volume data sources |
| Machine Learning (ML) Extraction | Unstructured (e.g., documents) | 98-99% accuracy; 40% reduction in processing time (e.g., loan applications) [89] | Processing complex documents like invoices, clinical reports, and research papers |
For unstructured data, which constitutes roughly 90% of organizational data, ML extraction methods represent a powerful single-agent AI approach [89]. These systems, which often combine Optical Character Recognition (OCR) and Natural Language Processing (NLP), can achieve 98-99% accuracy, far surpassing manual methods [89]. The integration of these single-agent AI tools into human workflows creates a multi-agent system. For instance, a financial institution used an ML-driven system to cut loan application processing time by 40%, a task that would have involved humans reviewing the AI's output and making final decisions [89]. In clinical research, a scoping review of RCTs found that 81% reported positive primary endpoints, with a significant focus on diagnostic yield and performance, showing AI's potent single-agent capabilities that can augment human clinicians [90].
Analysis of Key Experimental Protocols
Understanding the experimental design behind this evidence is crucial for assessing its validity. The following protocols are representative of the rigorous methodologies used in this field.
Protocol 1: Meta-Analysis of Human-AI Synergy
This protocol aimed to quantify synergy in human-AI systems across diverse tasks [87].
- Objective: To determine when combinations of humans and AI are better than either alone.
- Data Sources: An interdisciplinary search of databases (ACM Digital Library, Web of Science, AIS eLibrary) for studies published between January 2020 and June 2023.
- Eligibility Criteria: Included original human-participants experiments that evaluated the performance of humans alone, AI alone, and human-AI combinations.
- Data Extraction & Synthesis: Two independent reviewers screened titles/abstracts and conducted full-text reviews. A three-level meta-analytic model was used to synthesize 370 unique effect sizes from 106 experiments. The primary outcome was "human-AI synergy" (combination outperforms both alone), with a secondary outcome of "human augmentation" (combination outperforms human alone).
- Moderator Analysis: Investigated the impact of task type (decision vs. creation), data modality, and the relative performance of humans and AI alone.
Protocol 2: RCT Evaluation of AI in Clinical Practice
This scoping review focused on the highest tier of evidence: randomized controlled trials of AI in real-world clinical settings [90].
- Objective: To examine the state of RCTs for AI algorithms integrated into clinical practice.
- Data Sources: Systematic searches of PubMed, SCOPUS, CENTRAL, and the International Clinical Trials Registry Platform (2018-2023).
- Eligibility Criteria: Included RCTs where the intervention had a substantial AI component (e.g., neural networks), was integrated into clinical practice, and influenced patient management. Excluded linear risk scores and non-integrated interventions.
- Data Extraction: Two independent investigators performed screening. Data on study location, participant characteristics, clinical task, primary endpoint, and results were extracted and verified.
- Outcome Classification: Primary endpoints were classified into four groups: diagnostic yield/performance, clinical decision making, patient behaviour/symptoms, and care management.
The workflow below illustrates the rigorous, multi-stage process for identifying and synthesizing evidence in a systematic review and meta-analysis, as used in the key studies cited.
Visualizing the Determinants of Hybrid Performance
The performance of a multi-agent system is not random; it is heavily influenced by specific, identifiable factors. The meta-analysis by [87] identified two key moderators that significantly affect the outcome of human-AI collaboration.
Task Type is a primary determinant. The analysis found "performance losses in tasks that involved making decisions and significantly greater gains in tasks that involved creating content" [87]. This suggests that for procedural, data-synthesis tasks common in data extraction, single-agent AI might be highly effective, while creative tasks like generating a research hypothesis benefit more from collaboration.
Furthermore, the relative performance of the human and AI alone is critical. The study found that "when humans outperformed AI alone, we found performance gains in the combination, but when AI outperformed humans alone, we found losses" [87]. This creates a clear decision tree for researchers, illustrated below.
The Researcher's Toolkit: Essential Reagents & Materials
Implementing and studying these systems requires a suite of methodological and technological tools. The table below details key solutions referenced in the featured experiments.
Table 3: Research Reagent Solutions for Human-AI Systems
| Item | Function & Rationale |
|---|---|
| Covidence Review Software | A primary screening tool for systematic reviews and meta-analyses; streamlines the title/abstract and full-text review process with dual independent reviewers to minimize bias [90]. |
| Three-Level Meta-Analytic Model | A statistical model for synthesizing multiple effect sizes from single studies; accounts for within-study and between-study variance, providing a more robust pooled estimate [87]. |
| RCTs with Triple-Arms | The gold-standard experimental design for comparison, featuring human-only, AI-only, and human-AI combination arms. Essential for isolating the pure effect of collaboration [87] [88]. |
| Apache NiFi | An open-source ETL (Extract, Transform, Load) tool for automating data flows; enables real-time data processing and integration from diverse sources, crucial for building data pipelines [89]. |
| ML Extraction Platforms (e.g., Docsumo, KlearStack) | Platforms combining OCR and NLP to process unstructured documents; achieve near-perfect accuracy and are used in experiments to benchmark AI performance against manual methods [89]. |
| CONSORT-AI Reporting Guidelines | An extension of the CONSORT statement for randomized trials involving AI interventions; improves the transparency, reproducibility, and quality of AI clinical trial reporting [90]. |
The current evidence demonstrates that there is no universal "best" paradigm for data extraction and research tasks. The choice between single-agent and multi-agent systems is highly context-dependent. Single-agent AI systems excel in structured, high-volume, data-driven tasks like batch data extraction from standardized documents, often achieving superior speed and accuracy [89]. In contrast, multi-agent human-AI systems show their greatest value in complex, creative, or nuanced tasks where human intuition, contextual understanding, and oversight are required to guide the AI's analytical power [87] [88].
Future research should move beyond asking "which is better" and focus on optimizing the interaction design within multi-agent systems. Promising areas include developing more intuitive interfaces for human-AI communication, establishing clear governance and accountability frameworks [91], and creating AI systems that can better assess and communicate their own uncertainty to human partners. For researchers and drug development professionals, the path forward involves a disciplined, evidence-based approach: identify the core task, benchmark the performance of human and AI single-agents, and strategically deploy collaboration only where the evidence indicates a true synergistic potential exists.
The automation of data extraction from text and images represents a critical frontier in computational research, directly impacting fields such as drug development where high-throughput analysis of scientific literature, lab reports, and experimental imagery is essential. The central challenge lies in selecting an optimal system architecture that balances accuracy, cost, and complexity for a given data type. This guide objectively compares the performance of two predominant architectural paradigms—single-agent systems (SAS) and multi-agent systems (MAS)—in handling structured text and complex image-based data extraction tasks. Framed within broader research on AI system design, this analysis synthesizes recent experimental data to provide researchers with a evidence-based framework for selecting and deploying effective data extraction solutions.
Performance Comparison: Single-Agent vs. Multi-Agent Systems
The choice between a single-agent and a multi-agent system involves significant trade-offs. The following table synthesizes their core characteristics based on empirical studies and implementation reports [6] [4] [14].
Table 1: Fundamental Characteristics of Single vs. Multi-Agent Systems
| Characteristic | Single-Agent System (SAS) | Multi-Agent System (MAS) |
|---|---|---|
| Core Architecture | A single LLM handles the entire task from start to finish [4]. | Multiple autonomous, specialized agents collaborate [4]. |
| Typical Workflow | Monolithic, sequential processing within a single loop [4]. | Orchestrated patterns (e.g., chaining, routing, parallelization) [14]. |
| Development & Debugging | Faster to prototype; easier to trace problems [4]. | Requires coordination; more complex debugging due to distributed logic [4]. |
| Inference Cost & Latency | Generally lower per task [6] [4]. | Potentially higher due to multiple LLM calls [4]. |
| Optimal Use Case | Simple, well-scoped tasks resolvable in one logical pass [4]. | Complex, multi-step tasks requiring specialized skills or error checking [4] [14]. |
The performance of these architectures is further illuminated by recent empirical data. A 2025 study comparing SAS and MAS across various agentic applications revealed that the performance gap is narrowing with the advent of more powerful frontier LLMs, but significant differences remain in complex scenarios [6].
Table 2: Empirical Performance and Cost Trade-offs (2025 Study Data) [6]
| Application Scenario | SAS Accuracy (%) | MAS Accuracy (%) | MAS Cost & Latency vs. SAS |
|---|---|---|---|
| Simple Structured Data Extraction | High (Benchmark: ~99%) | Comparable | Significantly Higher |
| Complex Document Understanding | Lower | 1.1% - 12% Higher | Moderately Higher |
| Dynamic Task Decomposition | Struggles | Superior | Varies by Workflow |
Experimental Data: Text Extraction Tools and Performance
The performance of any agentic system is contingent on the underlying text recognition engine. The following data from 2025 benchmarks provides a comparative overview of leading OCR and multi-modal LLM tools [92] [93].
Table 3: 2025 OCR & Multi-Modal LLM Benchmarking Results
| Tool Name | Printed Text Accuracy | Handwriting Accuracy | Structured Doc Support | Key Strengths |
|---|---|---|---|---|
| Google Document AI | ~98% [93] | High [93] | 9/10 (Excellent semantics) [92] | High overall accuracy, strong semantic field detection [92]. |
| Amazon Textract | ~99% (excl. outliers) [93] | High (with exceptions) [93] | 8/10 (Good for invoices/tables) [92] | Robust table and form extraction, fast processing [92]. |
| Azure Form Recognizer | ~99.8% (Pure OCR) [93] | Moderate [93] | 6/10 (Layout, no semantics) [92] | Excellent layout mapping, high-speed processing [92]. |
| GPT-4 Vision / Claude 3.7 | High [94] | Highest among benchmarks [93] | N/A (Contextual understanding) [94] | Superior contextual understanding, handles variable layouts [94]. |
| Tesseract OCR | >95% (Free/Open-source) [93] | Moderate [93] | N/A | Good for standard printed text, no cost [93]. |
Experimental Protocol for Tool Benchmarking
The quantitative data in Table 3 is derived from independent 2025 benchmarks. The methodology for these tests is summarized below [92] [93]:
- Objective: To evaluate the text extraction accuracy and document structure understanding of various OCR and multi-modal LLM tools.
- Dataset: Typically consists of a curated set of 30+ documents, including:
- Category 1 (Printed Text): Digital screenshots, emails, and reports [93].
- Category 2 (Handwriting): A mix of cursive and print-style handwritten samples, sometimes preprocessed (binarization, contrast increase) [93].
- Category 3 (Structured Documents): Invoices, forms, and tables in various formats (scanned PDFs, images) [92].
- Analysis Method: Output texts are compared to manually verified ground truth. Accuracy is often calculated using cosine similarity between the tool's output and the original text, which is less punitive to word order differences than Levenshtein distance [93].
- Evaluation Metrics: Primary metrics are text extraction accuracy (%) and scores for specialized capabilities like table extraction and structured document support [92].
System Architecture Workflows for Data Extraction
The logical relationship between a user's request, the system architecture, and the final extracted data can be visualized through the following workflows.
Single-Agent System Workflow
Multi-Agent System Workflow
The Researcher's Toolkit for Data Extraction
Selecting the right tools and architectures is fundamental to building an effective data extraction pipeline. The following table details key solutions and their functions in this domain.
Table 4: Essential Research Reagent Solutions for Data Extraction
| Solution / Reagent | Function in the Research Pipeline |
|---|---|
| Cloud OCR APIs (e.g., Google Document AI, AWS Textract) | Provide high-accuracy, pre-trained engines for converting images and PDFs into machine-readable text and structured data, serving as a foundation for any extraction pipeline [92] [93]. |
| Multi-Modal LLMs (e.g., GPT-4V, Claude 3.7, Gemini 2.5 Pro) | Act as powerful single agents capable of contextual understanding, able to handle documents with variable layouts without predefined templates [94]. |
| Agentic Frameworks (e.g., LangGraph, AutoGen) | Provide the "orchestration layer" for building multi-agent systems, managing state, routing between specialists, and enforcing interaction protocols [33] [14]. |
| Specialist Agent (Role-based Prompting) | A software pattern where a general-purpose LLM is assigned a specific role (e.g., "Validator," "Data Mapper") through prompt engineering, creating specialized components in a MAS [4] [14]. |
| Research Pad / Shared State | A software mechanism (e.g., shared memory, database) that allows agents in a MAS to read from and write to a common knowledge base, facilitating collaboration and context preservation [33]. |
The analysis of performance in text versus image-based data extraction reveals a nuanced landscape. For tasks involving high-quality, consistently formatted text, traditional OCR engines within a simple single-agent architecture often provide unbeatable speed and accuracy at a lower cost. Conversely, for complex, image-based data or documents with variable layouts, a multi-agent system leveraging multi-modal LLMs delivers superior accuracy and contextual understanding, despite its higher complexity and latency. The evolving capabilities of frontier LLMs are continuously shifting this balance, making hybrid approaches increasingly viable. The optimal design is not a static choice but a dynamic decision that must be tailored to the specific data characteristics, accuracy requirements, and resource constraints of the research task at hand.
Evaluating Cost-Benefit and Return on Investment for Research Organizations
This guide provides an objective comparison between single-agent and multi-agent AI systems, focusing on their application in data extraction and analysis for research organizations. The analysis is framed within a broader thesis examining the architectural trade-offs of these systems to inform strategic decision-making for scientists, researchers, and drug development professionals.
Artificial Intelligence (AI) agents are autonomous software entities that perceive their environment, reason about goals using large language models (LLMs) or other AI techniques, and take actions to achieve objectives [76]. In the context of research organizations, these agents can automate complex data extraction, analysis, and interpretation tasks that traditionally require significant human effort.
The fundamental distinction lies between single-agent systems, which utilize one autonomous agent to complete a task from start to finish, and multi-agent systems, which coordinate several specialized agents that communicate and divide work to reach a shared goal [23]. This architectural difference creates significant implications for implementation complexity, performance characteristics, and economic outcomes for research organizations.
Agentic AI systems have evolved from simple rule-based systems to sophisticated platforms capable of complex reasoning and task execution. Modern systems leverage techniques like Chain-of-Thought (CoT) training and ReAct (Reasoning + Acting) frameworks, enabling models to break problems into steps and use tools effectively [24] [76]. For research applications, particularly in data-intensive fields like drug development, these capabilities offer transformative potential for accelerating discovery while managing costs.
Performance and Economic Comparison
Understanding the quantitative and qualitative differences between single-agent and multi-agent systems is essential for research organizations making strategic technology investments. The table below summarizes key comparative metrics based on current implementations across various sectors.
Table 1: Comprehensive Comparison of Single-Agent vs. Multi-Agent AI Systems
| Evaluation Metric | Single-Agent Systems | Multi-Agent Systems |
|---|---|---|
| Architectural Characteristics | ||
| Number of Agents | One autonomous agent [23] | Multiple specialized agents (typically 5-25) [95] [23] |
| Decision-Making | Centralized [23] | Distributed or hierarchical [76] [23] |
| Coordination Overhead | None [23] | Significant (50-200ms per interaction) [95] |
| Implementation Factors | ||
| Initial Implementation Cost | Lower | $500K to $5M, depending on scope [95] |
| Implementation Timeline | Weeks to months | 6-18 months for full deployment [95] |
| Maintenance Cost (Annual) | Lower | 15-25% of initial implementation cost [95] |
| Performance Metrics | ||
| Task Accuracy for Simple Tasks | High (e.g., 87% for data extraction) [96] | Comparable for simple tasks [76] |
| Task Accuracy for Complex Tasks | Limited (e.g., 73% for multi-domain queries) [76] | Superior (e.g., 94% for multi-domain queries) [76] |
| Fault Tolerance | Single point of failure [23] | Robust; failure of one agent doesn't collapse system [23] |
| Problem-Solving Capability | Restricted to one perspective [23] | Distributed problem-solving with multiple perspectives [23] |
| Economic Outcomes | ||
| Return on Investment (ROI) | Good for narrow tasks | 200-400% within 12-24 months [95] |
| Annual Cost Savings | Moderate | $2.1-3.7 million (average across industries) [95] |
| Scalability | Limited scalability; linear complexity growth [23] | Highly scalable; agents can be added/removed dynamically [95] [23] |
Interpretation of Comparative Data
The data reveals that single-agent systems provide satisfactory performance for narrow, well-defined research tasks such as extracting predetermined data points from structured documents, where they can achieve accuracy comparable to established registries (mean 0.88, SD 0.06 vs. mean 0.90, SD 0.06) [96]. Their advantages include simpler design, faster implementation, lower communication overhead, and more predictable behavior [23].
Multi-agent systems demonstrate superior capabilities for complex research workflows that require diverse expertise, such as cross-referencing multiple data sources, validating findings, and generating comprehensive reports [76]. Despite higher initial costs and implementation complexity, they offer compelling long-term value through distributed intelligence, better fault tolerance, and specialized capabilities [95] [23]. Industries with complex data processing requirements report productivity gains of 35% and customer satisfaction improvements of 28% after implementing multi-agent systems [95].
Experimental Protocols and Validation
Protocol 1: Data Extraction Accuracy Study
Objective: To evaluate the performance of single-agent and multi-agent systems in extracting cost-effectiveness analysis (CEA) data from research publications.
Methodology:
- Data Source: 34 selected structured articles with 36 predetermined variables [96]
- Intervention Groups:
- Custom ChatGPT Model (GPT): Single-agent system implementing retrieval-augmented generation and chain-of-thought reasoning [96]
- Tufts CEA Registry (TCRD): Established manual data extraction registry serving as reference standard [96]
- Researcher-Validated Data (RVE): Gold standard with human expert validation [96]
- Evaluation Metrics: Concordance rates between GPT and RVE, TCRD and RVE, and GPT and TCRD across all variables [96]
- Statistical Analysis: Paired student's t-tests to assess differences in accuracy; concordance rates calculated across 36 variables [96]
Key Findings: The single-agent system (GPT) demonstrated comparable accuracy to the established registry (mean 0.88, SD 0.06 vs. mean 0.90, SD 0.06, P = .71) [96]. Performance varied across variable types, with the single-agent system outperforming in capturing "Population and Intervention Details" but struggling with complex variables like "Utility" [96].
Protocol 2: Multi-Domain Task Handling Study
Objective: To compare the ability of single-agent and multi-agent systems to handle complex, multi-domain research queries.
Methodology:
- Task Design: Complex query requiring coordination across three domains: "I need to dispute this charge, update my address, AND get a loan pre-approval" [76]
- Intervention Groups:
- Evaluation Metrics:
- Accuracy percentage
- Task completion time
- Compliance with operational rules
Key Findings: The single-agent system achieved 73% accuracy, hallucinated policies, mixed up accounts, and generated responses violating compliance rules [76]. The multi-agent system achieved 94% accuracy and completed the complex query in under 90 seconds through specialized coordination [76].
Architectural Visualization
The architectural differences between single-agent and multi-agent systems significantly impact their implementation and performance characteristics in research settings.
Diagram 1: AI System Architectures Comparison
The single-agent architecture follows a linear workflow where one reasoning engine handles all aspects of task execution, while the multi-agent system employs specialized agents coordinated through a central orchestrator that manages task decomposition and output synthesis [76].
Research Reagent Solutions
Implementing AI agent systems in research organizations requires both technical infrastructure and methodological components. The table below details essential "research reagents" for developing effective AI agent solutions.
Table 2: Essential Research Reagent Solutions for AI Agent Implementation
| Component | Function | Examples & Specifications |
|---|---|---|
| Large Language Models (LLMs) | Core reasoning engines that process and generate inferences to interpret instructions and provide responses [5]. | GPT-4 (OpenAI), Claude (Anthropic), PaLM (Google), LLaMA (Meta) [5] |
| Orchestration Frameworks | Manage workflow coordination, task decomposition, and inter-agent communication [76]. | LangGraph, Supervisor patterns, Hierarchical controllers [22] [76] |
| Tool Integration APIs | Enable agents to interact with external systems, databases, and computational resources [5]. | Function calling protocols, REST API connectors, database drivers [24] [76] |
| Communication Protocols | Standardized methods for information sharing and coordination between agents [95]. | Message passing, shared databases, event-driven notifications [95] |
| Evaluation Benchmarks | Standardized datasets and metrics to assess performance on research-specific tasks [19]. | Legal benchmarks, scientific Q&A datasets, data extraction accuracy metrics [96] [19] |
| Security & Compliance Frameworks | Ensure data privacy, regulatory compliance, and auditability of agent decisions [95] [97]. | Encryption protocols, compliance frameworks (GDPR, HIPAA), audit logs [95] |
Decision Framework and Implementation Pathway
Selecting the appropriate architecture depends on specific research requirements, organizational capabilities, and strategic objectives. The following decision framework provides guidance for research organizations.
Diagram 2: Architecture Selection Decision Framework
When to Select Single-Agent Systems
Research organizations should consider single-agent systems when:
- Tasks are simple, well-defined, and require no collaboration between domains [23]
- The research environment is controlled and predictable [23]
- Fast decision-making is a priority and resource usage must be minimized [76]
- Ease of design, debugging, and maintenance are primary concerns [23]
- All necessary context fits within one model's context window [76]
When to Select Multi-Agent Systems
Multi-agent systems are preferable when:
- Research tasks are complex, dynamic, or involve multiple objectives [23]
- Collaboration, negotiation, or distributed problem-solving is needed [23]
- Scalability and adaptability are important for future growth [95]
- Fault tolerance and robustness are necessary for uninterrupted operation [23]
- Parallel processing or multiple specialized perspectives improve outcomes [76]
The choice between single-agent and multi-agent systems represents a strategic decision with significant implications for research organizations' operational efficiency and economic outcomes. Single-agent systems offer simplicity, lower initial costs, and faster implementation for well-defined research tasks, demonstrating particular strength in standardized data extraction applications where they can achieve accuracy comparable to established manual methods [96].
Multi-agent systems, despite higher initial investment and implementation complexity, deliver superior performance for complex, multi-domain research tasks through specialized coordination [76]. The documented ROI of 200-400% within 12-24 months and substantial annual cost savings make them economically compelling for organizations with complex research workflows [95].
Research organizations should approach the decision through careful assessment of their specific task requirements, technical capabilities, and strategic objectives. As AI agent technologies continue maturing, with the autonomous agents market projected to grow from $4.35 billion in 2025 to $103.28 billion by 2034, these architectural considerations will become increasingly central to research organizations' technological competitiveness and operational efficiency [97].
Conclusion
The choice between single-agent and multi-agent systems for data extraction is not a matter of superiority, but of strategic fit. Single-agent systems offer a straightforward, resource-efficient solution for well-defined, linear tasks. In contrast, multi-agent architectures provide the collaborative intelligence, scalability, and fault tolerance necessary for the complex, multi-faceted data extraction workflows common in biomedical research and systematic reviews. The emerging paradigm is not full automation, but powerful AI-human collaboration, where AI handles scalable data processing and humans provide crucial oversight. Future directions involve developing more sophisticated orchestration frameworks, establishing robust governance and audit trails for regulatory compliance, and creating domain-specific agents fine-tuned for clinical and pharmacological data. For the field of drug development, embracing these collaborative systems promises to accelerate evidence synthesis, reduce manual error, and ultimately bring treatments to patients faster and with greater confidence.
References
- 1. Single vs Multi-Agent System? [https://www.philschmid.de/single-vs-multi-agents]
- 2. LLMs and Multi - Agent : The Future of AI in Systems 2025 [https://www.classicinformatics.com/blog/how-llms-and-multi-agent-systems-work-together-2025]
- 3. Multi-Agent Systems in AI: Concepts & Use Cases 2025 [https://www.kubiya.ai/blog/what-are-multi-agent-systems-in-ai]
- 4. When to Use Multi-Agent Systems: Choosing Between ... [https://www.netguru.com/blog/multi-agent-systems-vs-solo-agents]
- 5. -AI Multi in Agents : Key Insights, Examples, and... Systems 2025 [https://ioni.ai/post/multi-ai-agents-in-2025-key-insights-examples-and-challenges]
- 6. Single-agent or Multi-agent Systems? Why Not Both? [https://arxiv.org/abs/2505.18286]
- 7. More Agents Is All You Need: A Deep Dive into Scaling Multi - Agent ... [https://medium.com/@mahadheer/more-agents-is-all-you-need-a-deep-dive-into-scaling-multi-agent-systems-b0d3a83b47c1]
- 8. Test and validate multi - agent in system performance 2025 [https://kanerika.com/blogs/how-to-test-and-validate-multi-agent-system-performance/]
- 9. Guide to AI Agent Architecture with Diagrams [https://www.designveloper.com/blog/ai-agent-architecture-diagram/]
- 10. Agentic AI Architecture: Types, Components & Best Practices [https://www.exabeam.com/explainers/agentic-ai/agentic-ai-architecture-types-components-best-practices/]
- 11. Single Agent vs Multi Agent AI: Which Is Better? [https://www.kubiya.ai/blog/single-agent-vs-multi-agent-in-ai]
- 12. AI Agents vs. Multi-agent systems: From solo expertise to ... [https://www.talan.com/global/en/ai-agents-vs-multi-agent-systems-solo-expertise-orchestrated-collective-intelligence]
- 13. Multi-Agent AI Systems: Orchestrating AI Workflows [https://www.v7labs.com/blog/multi-agent-ai]
- 14. Single AI Agent Versus Multiple Agents - Azure Logic Apps [https://learn.microsoft.com/en-us/azure/logic-apps/single-versus-multiple-agents]
- 15. How we built our multi-agent research system [https://www.anthropic.com/engineering/multi-agent-research-system]
- 16. A practical guide to the architectures of agentic applications [https://www.speakeasy.com/mcp/using-mcp/ai-agents/architecture-patterns]
- 17. Single Agent vs Multi-Agent Systems: Choosing the Right ... [https://medium.com/snowflake/single-agent-vs-multi-agent-systems-choosing-the-right-ai-architecture-356b8566d114]
- 18. Measuring the Impact of Early-2025 AI on Experienced ... [https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/]
- 19. From single-agent to multi-agent: a comprehensive review ... [https://www.oaepublish.com/articles/aiagent.2025.06]
- 20. Google New Color Palette [https://www.color-hex.com/color-palette/51381]
- 21. Data Visualization Colors: Best Practices & Palettes (2025) [https://letdataspeak.com/mastering-color-in-data-visualizations/]
- 22. Agentic AI: Single vs Multi-Agent Systems [https://medium.com/data-science-collective/agentic-ai-single-vs-multi-agent-systems-e5c8b0e3cb28]
- 23. Single-Agent vs. Multi-Agent Systems [https://kanerika.com/blogs/single-or-multi-agent-see-which-ai-wins/]
- 24. AI Agents in 2025: Expectations vs. Reality [https://www.ibm.com/think/insights/ai-agents-2025-expectations-vs-reality]
- 25. Agent-based multimodal information extraction for ... [https://www.nature.com/articles/s41524-025-01674-7]
- 26. [2507.20230] A Multi-Agent System Enables Versatile ... [https://arxiv.org/abs/2507.20230]
- 27. Single Agent vs Multi Agent in AI: Key Differences in 2025 [https://www.youngurbanproject.com/single-agent-vs-multi-agent-in-ai/]
- 28. Benefits of Multi-Agent Systems [https://galileo.ai/blog/benefits-of-multi-agent-systems]
- 29. Multi-agent LLMs in 2025 [+frameworks] [https://www.superannotate.com/blog/multi-agent-llms]
- 30. Middle Ground – Centralized vs. Decentralized Decision-Making [https://www.sorenkaplan.com/middle-ground-centralized-vs-decentralized-decision-making/]
- 31. Centralized vs Distributed System [https://www.geeksforgeeks.org/computer-networks/centralized-vs-distributed-system/]
- 32. Centralized vs. Distributed IT Infrastructure [https://www.scalecomputing.com/resources/centralized-vs-distributed-it-infrastructure]
- 33. Agentic AI: Single vs Multi-Agent Systems [https://towardsdatascience.com/agentic-ai-single-vs-multi-agent-systems/]
- 34. Centralized vs Decentralized Agile Transformations—Pros ... [https://agilevelocity.com/blog/centralized-vs-decentralized-agile-transformations/]
- 35. Centralized vs distributed data teams [https://deepnote.com/guides/data-science-and-analytics/centralized-vs-distributed-data-teams]
- 36. Centralized vs Decentralized Decision Making [https://platinumedge.com/centralized-vs-decentralized-decision-making-which-one-is-better]
- 37. What is Multi-Agent Orchestration? An Overview [https://www.talkdesk.com/blog/multi-agent-orchestration/]
- 38. Workflow for prompt chaining - AWS Prescriptive Guidance [https://docs.aws.amazon.com/prescriptive-guidance/latest/agentic-ai-patterns/workflow-for-prompt-chaining.html]
- 39. Building Effective AI Agents [https://www.anthropic.com/engineering/building-effective-agents]
- 40. The Architecture Behind Autonomous AI Agents - Ali Shamaei [https://ashamaei.medium.com/the-architecture-behind-autonomous-ai-agents-core-execution-patterns-c9eead631f79?source=rss------artificial_intelligence-5]
- 41. Orchestrating Multi-Agent Workflows with MCP & A2A [https://www.iguazio.com/blog/orchestrating-multi-agent-workflows-with-mcp-a2a/]
- 42. Build a Multiple-Agent Workflow Automation Solution with ... [https://learn.microsoft.com/en-us/azure/architecture/ai-ml/idea/multiple-agent-workflow-automation]
- 43. Benchmarking Multiple Large Language Models for ... [https://www.mdpi.com/1999-4893/18/5/296]
- 44. Enhancing diagnostic capability with multi-agents ... [https://www.nature.com/articles/s41746-025-01550-0]
- 45. Automated Clinical Trial Data Analysis and Report ... [https://www.mdpi.com/2673-2688/6/8/188]
- 46. Approach to machine learning for extraction of real-world ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10541019/]
- 47. Agents for Change: Artificial Intelligent Workflows for ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11889410/]
- 48. Comparing the accuracy of AI-assisted data extraction ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12593456/]
- 49. Ai Based Data Extraction in 2025 [https://callin.io/ai-based-data-extraction-2/]
- 50. Document-level event argument extraction with dual- ... [https://link.springer.com/article/10.1007/s44443-025-00350-6]
- 51. Claude vs. GPT-4: Detailed Comparison - Rezolve.ai [https://www.rezolve.ai/blog/claude-vs-gpt-4]
- 52. High-throughput biomedical relation extraction for semi ... [https://bmcmedinformdecismak.biomedcentral.com/articles/10.1186/s12911-025-03204-3]
- 53. Top Recent LLM Models Revolutionizing... - Omics tutorials [https://omicstutorials.com/top-recent-llm-models-revolutionizing-bioinformatics-research-in-2025/]
- 54. Revolutionizing Healthcare with Multimodal AI... - DEV Community [https://dev.to/mckanth/revolutionizing-healthcare-with-multimodal-ai-introducing-contact-doctors-biomedical-api-5g6m]
- 55. Single-Agent vs Multi-Agent Systems: Two Paths for the ... [https://www.digitalocean.com/resources/articles/single-agent-vs-multi-agent]
- 56. What are multi-agent systems? [https://www.box.com/resources/what-are-multi-agent-systems]
- 57. 23 AI Agent Performance Metrics for Leaders - Multimodal [https://www.multimodal.dev/post/ai-agent-performance-metrics-for-leaders]
- 58. 5 Key Advantages of Multi-Agent Systems Over Single ... [https://www.rapidinnovation.io/post/multi-agent-systems-vs-single-agents]
- 59. AI Agent Observability vs. Benchmarking vs. Evaluation [https://galileo.ai/blog/ai-agent-measurement-guide-observability-benchmarking-evaluation]
- 60. Hallucination Mitigation using Agentic AI Natural Language ... [https://arxiv.org/html/2501.13946v1]
- 61. Mitigating reasoning hallucination through Multi-agent ... [https://www.sciencedirect.com/science/article/abs/pii/S0957417424025909]
- 62. Mitigating LLM Hallucinations Using a Multi-Agent ... [https://www.mdpi.com/2078-2489/16/7/517]
- 63. How to Prevent LLM Hallucinations: 5 Proven Strategies [https://www.voiceflow.com/blog/prevent-llm-hallucinations]
- 64. Reducing hallucinations in large language models with ... [https://aws.amazon.com/blogs/machine-learning/reducing-hallucinations-in-large-language-models-with-custom-intervention-using-amazon-bedrock-agents/]
- 65. Advanced Techniques for Hallucination Detection in AI [https://sparkco.ai/blog/advanced-techniques-for-hallucination-detection-in-ai]
- 66. Challenges in Multi-Agent LLMs: Navigating Coordination and ... [https://gafowler.medium.com/challenges-in-multi-agent-llms-navigating-coordination-and-context-management-20661f9f2bfa]
- 67. A Multi-Agent System for Extracting and Querying Financial ... [https://arxiv.org/html/2505.19197v1]
- 68. Single-Agent vs. Multi-Agent Systems [https://kanerika.com/unlisted-blogs/single-agent-vs-multi-agent-systems/]
- 69. How do multi-agent systems ensure fault tolerance? [https://milvus.io/ai-quick-reference/how-do-multiagent-systems-ensure-fault-tolerance]
- 70. Multi-Agent AI Systems: When to Expand From a Single ... [https://www.telusdigital.com/insights/data-and-ai/article/multi-agent-ai-systems-when-to-expand]
- 71. Harnessing Largeâ€Language Models for Efficient Data ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12559671/]
- 72. Development of a machine learning model for automatic ... [https://www.nature.com/articles/s41598-025-23461-6]
- 73. How to Define Success in Multi-Agent AI Systems [https://galileo.ai/blog/success-multi-agent-ai]
- 74. Critical Assessment of Large Language Models' (ChatGPT ... [https://ai.jmir.org/2025/1/e68097]
- 75. From data silos to insights: the PRINCE multi-agent ... [https://www.frontiersin.org/journals/artificial-intelligence/articles/10.3389/frai.2025.1636809/full]
- 76. Single-Agent vs Multi-Agent AI Systems - Gino MarÃn [https://www.ginomarin.com/articles/single-vs-multi-agent-ai]
- 77. Implement human-in-the-loop confirmation with ... [https://aws.amazon.com/blogs/machine-learning/implement-human-in-the-loop-confirmation-with-amazon-bedrock-agents/]
- 78. Human-in-the-Loop (HitL) Agentic AI for High-Stakes ... [https://onereach.ai/blog/human-in-the-loop-agentic-ai-systems/]
- 79. Preventing Model Collapse in 2025 with Human-in-the-Loop ... [https://humansintheloop.org/what-is-model-collapse-and-why-its-a-2025-concern/]
- 80. Future of Human-in-the-Loop AI (2025) - Emerging Trends ... [https://parseur.com/blog/future-of-hitl-ai]
- 81. A Comprehensive Benchmark to Evaluate Agent ... [https://arxiv.org/html/2509.10769v1]
- 82. Benchmarking Multi-Agent Architectures [https://blog.langchain.com/benchmarking-multi-agent-architectures/]
- 83. Why Multi-Agent Systems Are Surpassing Single-Agent AI [https://medium.com/@bluebashco/why-multi-agent-systems-are-outpacing-single-agent-ai-in-2025-932d5ec1faac]
- 84. Single-agent and multi-agent architectures - Dynamics 365 [https://learn.microsoft.com/en-us/dynamics365/guidance/resources/contact-center-multi-agent-architecture-design]
- 85. Mastering Agent Performance Metrics for 2025 Success [https://sparkco.ai/blog/mastering-agent-performance-metrics-for-2025-success]
- 86. Top Tools for AI Agent Monitoring in 2025 [https://www.getmaxim.ai/articles/top-tools-for-ai-agent-monitoring-in-2025/]
- 87. When combinations of humans and AI are useful [https://www.nature.com/articles/s41562-024-02024-1]
- 88. When humans and AI work best together [https://mitsloan.mit.edu/ideas-made-to-matter/when-humans-and-ai-work-best-together-and-when-each-better-alone]
- 89. Best Data Extraction Patterns in 2025 [https://blog.dreamfactory.com/best-data-extraction-patterns-in-2025]
- 90. Randomised controlled trials evaluating artificial ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11068159/]
- 91. How Human–AI Collaboration Redefines High Performance [https://www.dasa.org/blog/how-human-ai-collaboration-redefines-high-performance/]
- 92. OCR Ranking 2025 – Comparison of the Best Text ... [https://pragmile.com/ocr-ranking-2025-comparison-of-the-best-text-recognition-and-document-structure-software/]
- 93. OCR Benchmark: Text Extraction / Capture Accuracy [https://research.aimultiple.com/ocr-accuracy/]
- 94. Document Data Extraction in 2025: LLMs vs OCRs [https://www.vellum.ai/blog/document-data-extraction-in-2025-llms-vs-ocrs]
- 95. Multi-Agent AI Systems in 2025: Key Insights, Use Cases & ... [https://terralogic.com/multi-agent-ai-systems-why-they-matter-2025/]
- 96. Use of Large Language Models to Extract Cost ... [https://pubmed.ncbi.nlm.nih.gov/40480458/]
- 97. Adoption of AI and Agentic Systems: Value, Challenges, and ... [https://cmr.berkeley.edu/2025/08/adoption-of-ai-and-agentic-systems-value-challenges-and-pathways/]